Introduction
![]()
Tiders is an open-source framework that simplifies getting data out of blockchains and into your favorite tools. Whether you are building a DeFi dashboard, tracking NFT transfers, or running complex analytics, Tiders handles the heavy lifting of fetching, cleaning, transforming and storing blockchain data.
Tiders is modular. A Tiders pipeline is built from four components:
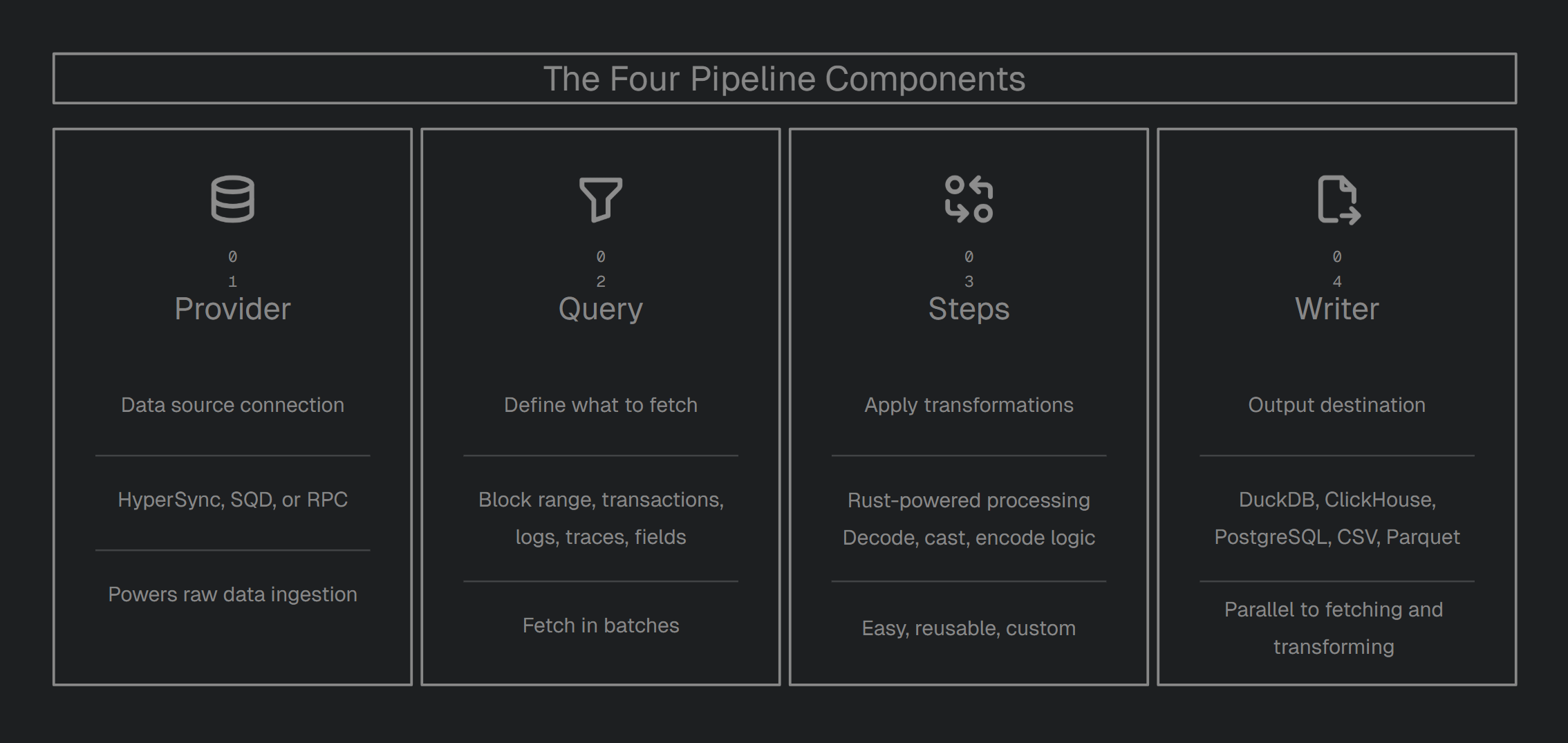
| Component | Description |
|---|---|
Provider | Data source (HyperSync, SQD, or RPC) |
Query | What data to fetch (block range, transaction, logs, filters, field selection) |
Steps | Transformations to apply (decode, cast, encode, custom) |
Writer | Output destination |
Why Tiders?
Most indexers lock you into a specific platform or database. Tiders is built to be modular, meaning you can swap parts in and out without breaking your setup:
- Swap Providers: Don’t like your current data source? Switch between HyperSync, SQD, or a standard RPC node by changing one line of code.
- Plug-and-Play data transformations: Need to decode smart contract events or change data types? Use our built-in Rust-powered steps or write your own custom logic.
- Write Anywhere: Send your data to a local DuckDB file for prototyping, or a production-grade ClickHouse or PostgreSQL instance when you’re ready to scale.
- Modular Reusable Pipelines: Protocols often reuse the same data structures. You don’t need write modules from scratch every time. Since Tiders pipelines are regular Python objects, you can build functions around them, reuse across pipelines, or set input parameters to customize as needed.
Two ways to use Tiders
| Mode | How | When to use |
|---|---|---|
| Python SDK | Write a Python script, import tiders | Full control, custom logic, complex pipelines |
| CLI (No-Code) | Write a YAML config, run tiders start | Quick setup, no Python required, standard pipelines |
Both modes share the same pipeline engine.
You can also use tiders codegen to generate a Python script from a YAML config — a quick way to move from no-code to full Python control.
Key Features
- Continuous Ingestion: Keep your datasets live and fresh. Tiders can poll the chain head to ensure your data is always up to date.
- Switch Providers: Move between HyperSync, SQD, or standard RPC nodes with a single config change.
- No Vendor Lock-in: Use the best data providers in the industry without being tied to their specific platforms or database formats.
- Custom Logic: Easily extend and customize your pipeline code in Python for complete flexibility.
- Advanced Analytics: Seamlessly works with industry-standard tools like Polars, Pandas, DataFusion and PyArrow as the data is fetched.
- Multiple Outputs: Send the same data to a local file and a production database simultaneously.
- Rust-Powered Speed: Core tasks like decoding and transforming data are handled in Rust, giving you massive performance without needing to learn a low-level language.
- Parallel Execution: Tiders doesn’t wait around. While it’s writing the last batch of data to your database, it’s already fetching and processing the next one in the background.
Data Providers
Connect to the best data sources in the industry without vendor lock-in. Tiders decouples the provider from the destination, giving you a consistent way to fetch data.
Tiders can support new providers. If your project has custom APIs to fetch blockchain data, especially ones that support server-side filtering, you can create a client for it, similar to the Tiders RPC client. Get in touch with us.
Transformations
Leverage the tools you already know. Tiders automatically convert data batch-by-batch into your engine’s native format, allowing for seamless, custom transformations on every incoming increment immediately before it is written.
| Engine | Data format in your function | Best for |
|---|---|---|
| Polars | Dict[str, pl.DataFrame] | Fast columnar operations, expressive API |
| Pandas | Dict[str, pd.DataFrame] | Familiar API, complex row-level operations |
| DataFusion | Dict[str, datafusion.DataFrame] | SQL-based transformations, lazy evaluation |
| PyArrow | Dict[str, pa.Table] | Zero-copy, direct Arrow manipulation |
Supported Output Formats
Whether local or a production-grade data lake, Tiders handles the schema mapping and batch-loading to your destination of choice.
| Destination | Type | Description |
|---|---|---|
| DuckDB | Database | Embedded analytical database, great for local exploration and prototyping |
| ClickHouse | Database | Column-oriented database optimized for real-time analytical queries |
| PostgreSQL | Database | General-purpose relational database with broad ecosystem support |
| Apache Iceberg | Table Format | Open table format for large-scale analytics on data lakes |
| Delta Lake | Table Format | Storage layer with ACID transactions for data lakes |
| Parquet | File | Columnar file format, efficient for analytical workloads |
| CSV | File | Plain-text format, widely compatible and easy to inspect |
Architecture
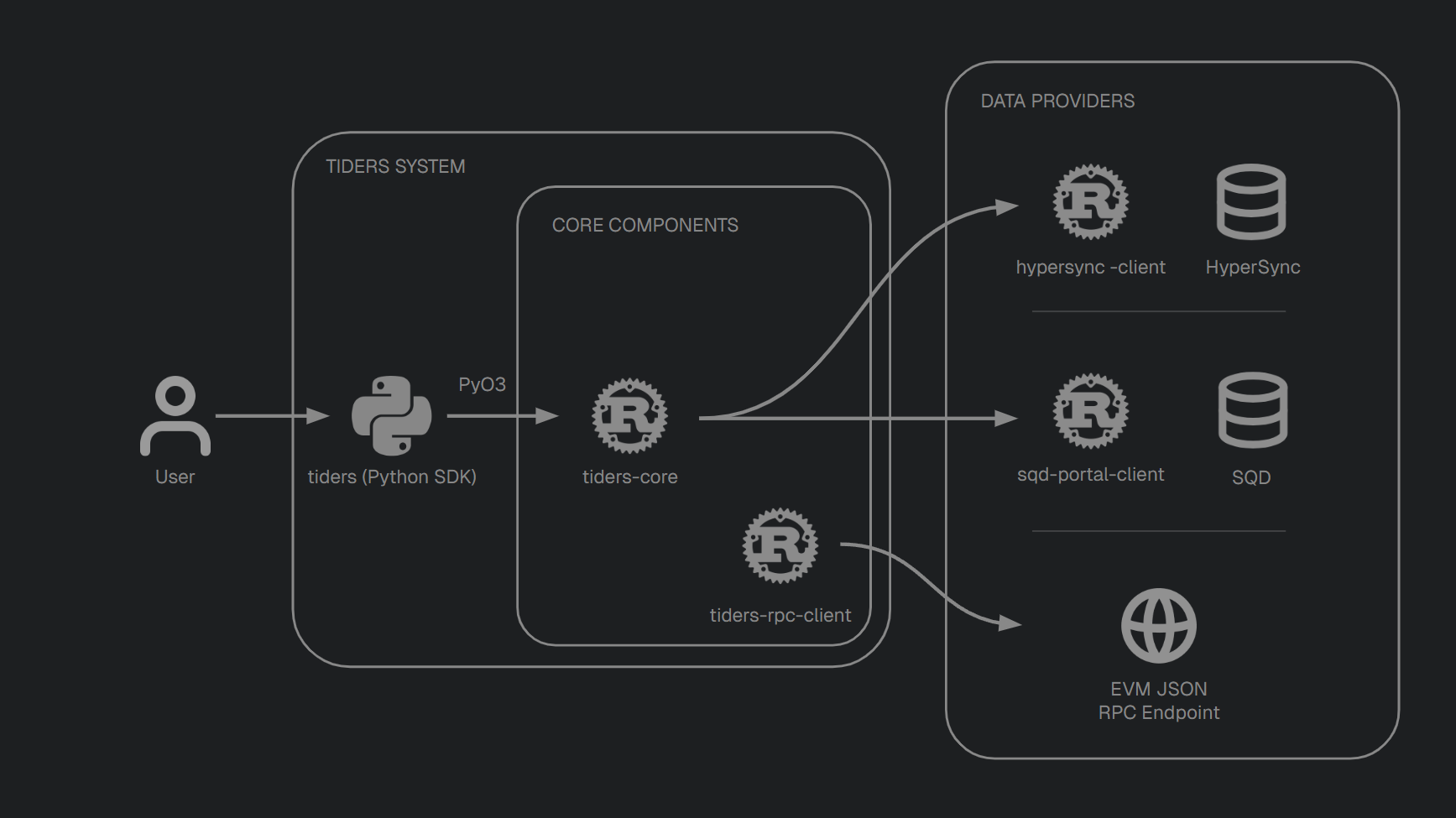
Tiders is composed of some repositories. 3 owned ones.
| Repository | Language | Role |
|---|---|---|
| tiders | Python | User-facing SDK for building pipelines |
| tiders-core | Rust | Core libraries for ingestion, decoding, casting, and schema |
| tiders-rpc-client | Rust | RPC client for fetching data from any standard EVM JSON-RPC endpoint |
API Reference
Auto-generated Rust API documentation is available at:
Installation
CLI (No-Code Mode)
To use tiders start with a YAML config, install the cli:
pip install "tiders"
This adds everything needed to run pipelines from a YAML file.
Combine with writer extras as needed:
pip install "tiders[duckdb]"
pip install "tiders[delta_lake]"
pip install "tiders[clickhouse]"
pip install "tiders[iceberg]"
Or install everything at once:
pip install "tiders[all]"
Python SDK
To create pipelines scripts in python, install Tiders as libraries. Tiders is published to PyPI as two packages:
tiders— the Python pipeline SDKtiders-core— pre-built Rust bindings (installed automatically as a dependency)
Using pip
pip install tiders tiders-core
Using uv (recommended)
uv pip install tiders tiders-core
Optional dependencies
Depending on your selected writer or transformation engine, you may need additional packages:
| Writer | Extra package |
|---|---|
| DuckDB | duckdb |
| ClickHouse | clickhouse-connect |
| PostgreSQL | postgresql |
| Iceberg | pyiceberg |
| DeltaLake | deltalake |
For transformation steps:
| Step engine | Extra package |
|---|---|
| Polars | polars |
| Pandas | pandas |
| DataFusion | datafusion |
uv pip install tiders[duckdb, polars] tiders-core
No-Code Quick Start
Run a blockchain data pipeline without writing Python — just a YAML config file.
1. Install
pip install "tiders[duckdb]"
2. Create a config file
Create tiders.yaml:
project:
name: erc20_transfers
description: Fetch ERC-20 Transfer events and write to DuckDB.
provider:
kind: rpc
url: "https://mainnet.gateway.tenderly.co" # or change to read from the .env file ${PROVIDER_URL}
contracts:
- name: erc20
address: "0xae78736Cd615f374D3085123A210448E74Fc6393" # rETH contract, we need a erc20 reference to download the ABI.
# An abi: ./erc20.abi.json config will be added after using CLI command `tiders abi` in this folder
writer:
kind: duckdb
config:
path: data/transfers.duckdb
# Optional: resume from the last written block if the pipeline is interrupted
# checkpoint:
# table: transfers
query:
kind: evm
from_block: 18000000
to_block: 18000100
logs:
- topic0: erc20.Events.Transfer.topic0
fields:
log: [address, topic0, topic1, topic2, topic3, data, block_number, transaction_hash, log_index]
steps:
- kind: evm_decode_events
config:
event_signature: erc20.Events.Transfer.signature
output_table: transfers
allow_decode_fail: true
hstack: true
- kind: cast_by_type
config:
from_type: "decimal256(76,0)"
to_type: "decimal128(38,0)"
allow_cast_fail: true
- kind: hex_encode
3. Environment Variables
Use ${VAR_NAME} placeholders anywhere in the YAML to keep secrets and environment-specific values out of your config file. This works for any string field — provider URLs, credentials, file paths, etc.
provider:
kind: rpc
url: ${PROVIDER_URL}
bearer_token: ${PROVIDER_BEARER_TOKEN}
At startup, the CLI automatically loads a .env file from the same directory as the config file, then substitutes all ${VAR_NAME} placeholders with their values. If a variable is referenced in the YAML but not defined, the CLI raises an error.
Create a .env file alongside your config:
PROVIDER_URL=https://mainnet.gateway.tenderly.co
PROVIDER_BEARER_TOKEN=12345678
You can also point to a different .env file using the --env-file flag:
tiders start --env-file /path/to/.env tiders.yaml
4. Download ABIs
Tiders CLI provides a command to make it easy to download ABIs defined in the YAML file and save them in the folder.
tiders abi
5. Run
tiders start
The CLI auto-discovers tiders.yaml in the current directory. However, you can also pass a path explicitly:
tiders start path/tiders.yaml
5. Generate a Python script (optional)
Once your YAML pipeline is working, you can generate an equivalent Python script using tiders codegen:
tiders codegen
This reads the same YAML file and outputs a standalone Python script that constructs and runs the same pipeline using the tiders Python SDK. By default, the output file is named after the project in snake_case (e.g. erc20_transfers.py). You can specify a custom output path with -o:
tiders codegen -o my_pipeline.py
This is useful when you want to move beyond YAML and customize the pipeline logic in Python — for example, adding custom transformation steps, conditional logic, or integrating with other libraries.
Next steps
- CLI Overview — CLI commands, flags, env var substitution, config auto-discovery
- CLI YAML Reference — full reference for all YAML sections
- rETH Transfer Example — complete annotated example
Your First Pipeline
This tutorial builds a pipeline that fetches ERC-20 transfer events from Ethereum and writes them to DuckDB.
Pipeline Anatomy
Every tiders pipeline has these parts:
- Contracts — optional, helper for contract information
- Provider — where to fetch data from
- Writer — where to write the output
- Checkpoint — optional, resume from the last written block
- Query — what data to fetch
- Steps — transformations to apply
Step 1: Define the Contracts
Contracts is an optional module that makes it easier to get contract information, such as Events, Functions and their params.
Use evm_abi_events and evm_abi_functions from tiders_core. These functions take a JSON ABI string and return a list[EvmAbiEvent] / list[EvmAbiFunction] with the fields described above.
from pathlib import Path
from tiders_core import evm_abi_events, evm_abi_functions
erc20_address = '0xae78736Cd615f374D3085123A210448E74Fc6393' # rETH token contract
erc20_abi_path = Path('/home/yulesa/repos/tiders/examples/first_pipeline/erc20.abi.json')
erc20_abi_json = erc20_abi_path.read_text()
# Build a dict of events keyed by name, e.g. erc20_events["Transfer"]["topic0"]
erc20_events = {
ev.name: {
'topic0': ev.topic0,
'signature': ev.signature,
'name_snake_case': ev.name_snake_case,
'selector_signature': ev.selector_signature,
}
for ev in evm_abi_events(erc20_abi_json)}
# Build a dict of functions keyed by name, e.g. erc20_functions["approve"]["selector"]
erc20_functions = {
fn.name: {
'selector': fn.selector,
'signature': fn.signature,
'name_snake_case': fn.name_snake_case,
'selector_signature': fn.selector_signature,
}
for fn in evm_abi_functions(erc20_abi_json)}
Step 2: Define the Provider
from tiders_core.ingest import ProviderConfig, ProviderKind
provider = ProviderConfig(
kind=ProviderKind.RPC,
url='https://mainnet.gateway.tenderly.co',
)
Available providers: HYPERSYNC, SQD, RPC.
Step 3: Configure the Writer
The writer defines where transformed data is stored. DuckDB creates a local database file. Other options include ClickHouse, Delta Lake, Iceberg, PostgreSQL, PyArrow Dataset (Parquet), and CSV.
from tiders.config import DuckdbWriterConfig, Writer, WriterKind
writer = Writer(
kind=WriterKind.DUCKDB,
config=DuckdbWriterConfig(path='data/transfers.duckdb'),
)
Step 4: Configure the Checkpoint (optional)
The checkpoint lets the pipeline resume from where it left off after an interruption. At startup, tiders reads MAX(column) from the specified table and advances from_block to that value plus one. If the table is empty or does not exist, the configured from_block is used unchanged.
from tiders.config import CheckpointConfig
checkpoint = CheckpointConfig(
table="transfers", # table to read the max block from
column="block_number", # default, can be omitted
writer_index=0, # default, can be omitted
)
Step 5: Define the Query
The query defines what data to fetch: block range, filters, and fields.
from tiders_core.ingest import Query, QueryKind
from tiders_core.ingest import evm
query = Query(
kind=QueryKind.EVM,
params=evm.Query(
from_block=18000000,
to_block=18000100,
logs=[evm.LogRequest(topic0=[erc20_events["Transfer"]["topic0"]])],
fields=evm.Fields(
log=evm.LogFields(
log_index=True,
transaction_hash=True,
block_number=True,
address=True,
data=True,
topic0=True,
topic1=True,
topic2=True,
topic3=True,
),
),
),
)
Step 6: Add Transformation Steps
Steps are transformations applied to the raw data before writing. They run in order, each step’s output feeding into the next.
STEP 1 - EVM_DECODE_EVENTS:
Decodes the raw log data (topic1..3 + data) into named columns using the event signature.
- allow_decode_fail: if True, rows that fail to decode are kept (with nulls)
- hstack: if False, outputs only decoded columns; if True, append them to the original raw log columns
STEP 2 - HEX_ENCODE:
Casts all columns matching a source PyArrow type to a target type. Here it downcasts Decimal256 (the EVM uint256 wire type) to Decimal128(38,0) for DuckDB compatibility. With allow_cast_fail=True, values that overflow become null instead of raising an error.
STEP 3 - HEX_ENCODE:
Converts binary columns (addresses, hashes) to hex strings, making them human-readable and compatible with databases like DuckDB.
import pyarrow as pa
from tiders.config import CastByTypeConfig, EvmDecodeEventsConfig, HexEncodeConfig, Step, StepKind
steps = [
Step(
kind=StepKind.EVM_DECODE_EVENTS,
config=EvmDecodeEventsConfig(
event_signature="Transfer(address indexed from, address indexed to, uint256 amount)",
output_table="transfers",
allow_decode_fail=True,
hstack=True,
),
),
# Downcast Decimal256 (EVM uint256) to Decimal128 for DuckDB compatibility
Step(
kind=StepKind.CAST_BY_TYPE,
config=CastByTypeConfig(
from_type=pa.decimal256(76, 0),
to_type=pa.decimal128(38, 0),
allow_cast_fail=True,
),
),
Step(
kind=StepKind.HEX_ENCODE,
config=HexEncodeConfig(),
),
]
Step 7: Run the Pipeline
The Pipeline ties all parts together. run_pipeline() executes the full ingestion: fetch → transform → write.
import asyncio
from tiders import run_pipeline
from tiders.config import Pipeline
pipeline = Pipeline(
provider=provider,
writer=writer,
checkpoint=checkpoint, # optional
query=query,
steps=steps,
)
asyncio.run(run_pipeline(pipeline=pipeline))
Verify the Output
Verify the output by querying the DuckDB file using duckdb-cli:
duckdb data/transfers.db
SHOW TABLES;
SELECT * FROM transfers LIMIT 5;
Next Steps
- Learn about all available providers
- See the full list of transformation steps
- Explore more examples
Choosing a Database
tiders can write data to several backends. This guide helps you pick the right one and get it running.
Which Database Should I Use?
| Database | Good for | Setup difficulty |
|---|---|---|
| DuckDB | Getting started, local analysis, prototyping | None — runs in-process |
| PostgreSQL | Relational queries, joining with existing app data | Easy with Docker |
| ClickHouse | Fast analytics on large datasets, aggregations | Easy with Docker |
| Parquet files | File-based storage, sharing data, data lakes | None — writes to disk |
| CSV | Quick export, spreadsheets, simple interoperability | None — writes to disk |
| Iceberg / Delta Lake | Production data lakes with ACID transactions | Moderate — requires catalog or storage setup |
Just getting started? Use DuckDB. It requires no external services — the Your First Pipeline tutorial uses it.
Need a production database? Read on to set up PostgreSQL or ClickHouse with Docker.
DuckDB
DuckDB runs inside your Python process. No server, no Docker, no configuration.
Install
Install tiders with the DuckDB extra dependency.
pip install "tiders[duckdb]"
Querying your data in DuckDB
Open the database file directly using duckdb CLI:
duckdb data/output.duckdb
A few SQL commands to explore:
-- List all tables
SHOW TABLES;
-- Preview data
SELECT * FROM transfers LIMIT 10;
-- Count rows
SELECT count(*) FROM transfers;
-- Exit
.quit
PostgreSQL with Docker
PostgreSQL is a battle-tested relational database going back to 1996. As a row-oriented store, it underperforms in heavy analytical workloads compared to columnar databases like ClickHouse. Use it when you need to read data straight from a pipeline without post-ingestion transformation, or when you want to connect your pipeline data to an existing PostgreSQL instance.
Starting PostgreSQL with Docker
Tiders provides a ready-made Docker Compose file in the tiders/docker_postgres/ folder. Copy this file or paste its contents into your own docker-compose.yaml.
Copy the environment file and edit as needed:
cp .env.example .env
Start the container:
docker compose up -d
When you’re done, stop the database containers:
# Stop the container (data is preserved in the volume)
docker compose down
# Stop and delete all data
docker compose down -v
Install tiders with the PostgreSQL extra dependency.
pip install "tiders[postgresql]"
Querying your data in PostgreSQL with psql
psql is the interactive terminal for PostgreSQL. You can access it through your Docker container:
# Connect via Docker
docker exec -it pg_database psql -U postgres -d tiders
# Or if you have psql installed locally
psql -U postgres -d tiders -h localhost -p 5432
Common psql commands:
| Command | Description |
|---|---|
\l | List all databases |
\dt | List tables in the current database |
\d transfers | Describe a table’s columns and types |
\c dbname | Switch to a different database |
\? | Show all meta-commands |
\q | Exit psql |
Try some queries:
-- Preview your data
SELECT * FROM transfers LIMIT 10;
-- Count rows
SELECT count(*) FROM transfers;
-- Check the PostgreSQL version
SELECT version();
ClickHouse with Docker
ClickHouse is a columnar database built for analytics. It excels at aggregating millions of rows quickly — ideal for blockchain data analysis.
Starting ClickHouse with Docker
Tiders provides a ready-made Docker Compose file in the tiders/docker_clickhouse/ folder. Copy this file or paste its contents into your own docker-compose.yaml.
Copy the environment file and edit as needed:
cp .env.example .env
Start the container:
docker compose up -d
Install tiders with the ClickHouse extra dependency.
pip install "tiders[clickhouse]"
When you’re done, stop the database containers:
# Stop the container (data is preserved in the volume)
docker compose down
# Stop and delete all data
docker compose down -v
Querying your data in ClickHouse
clickhouse-client is the interactive terminal for ClickHouse. Access it through your Docker container:
# Connect via Docker
docker exec -it clickhouse-server clickhouse-client --user default --password secret --database tiders
# Or if you have clickhouse-client installed locally
clickhouse-client --host localhost --port 9000 --user default --password secret --database tiders
You can also use the ClickHouse Web SQL UI at http://localhost:8123/play (assuming default host and port).
Try some queries:
-- List all databases
SHOW DATABASES;
-- List tables in the current database
SHOW TABLES;
-- Show a table's columns and types
DESCRIBE tiders.transfers;
-- Set the default database (so you don't have to prefix with `tiders.`)
USE tiders;
-- Preview your data
SELECT * FROM transfers LIMIT 10;
-- Count rows
SELECT count() FROM transfers;
-- Exit the client (type `exit` or press Ctrl+D)
Parquet Files
Parquet is a column-oriented, binary file (not human-readable) format that offers significantly smaller file sizes, faster query performance, and built-in schema metadata compared to CSV (human-readable). Use it when you want file-based storage without running a database.
Parquet Visualizer is a VS Code extension that lets you browse and run SQL against Parquet files directly in the editor.
You can also read Parquet files with DuckDB, Pandas, Polars, or any tool that supports the format:
# With DuckDB (no server needed)
import duckdb
duckdb.sql("SELECT * FROM 'data/output/transfers/*.parquet' LIMIT 10").show()
# With Pandas
import pandas as pd
df = pd.read_parquet("data/output/transfers/")
# With Polars
import polars as pl
df = pl.read_parquet("data/output/transfers/")
Next Steps
- See the full Writers reference for all configuration options
- Build your first pipeline with the Your First Pipeline tutorial
- Explore examples for complete working pipelines
Development Setup
To develop locally across all repos, clone all three projects side by side:
git clone https://github.com/yulesa/tiders.git
git clone https://github.com/yulesa/tiders-core.git
git clone https://github.com/yulesa/tiders-rpc-client.git
Installing tiders from the local repo
If you want to modify tiders and test your changes without publishing to PyPI, install it in editable mode directly from your local clone:
cd tiders
pip install -e ".[all] ../tiders-core/python"
# If using uv
uv pip install -e ".[all] ../tiders-core/python"
The [all] extra installs every optional dependency (DuckDB, ClickHouse, Delta Lake, etc.). You can also install only the extras you need, e.g. ".[duckdb,cli]".
Building tiders-core and tiders-rpc-client from source
If you’re modifying tiders-rpc-client repo locally, you probably want tiders-core to build against your local version.
Build tiders-rpc-client locally:
cd tiders-rpc-client/rust
cargo build
Use local tiders-rpc-clientto build tiders-core, overriding the crates.io version:
cd tiders-core
# Build Rust crates with local tiders-rpc-client
cargo build --config 'patch.crates-io.tiders-rpc-client.path="../tiders-rpc-client/rust"'
# Build Python bindings with the same patch
cd python
maturin develop --config 'patch.crates-io.tiders-rpc-client.path="../../tiders-rpc-client/rust"'
# If using uv
maturin develop --uv --config 'patch.crates-io.tiders-rpc-client.path="../../tiders-rpc-client/rust"'
If you’re modifying tiders-core repo locally, you probably want tiders to use your local tiders-core version.
Build tiders-core as described above, or just cargo build if you haven’t modified tiders-rpc-client.
Persistent local development
For persistent local development, you can put this in tiders-core/Cargo.toml:
[patch.crates-io]
tiders-rpc-client = { path = "../tiders-rpc-client/rust" }
This avoids passing --config on every build command.
Configure tiders to use your local tiders-core Python package:
[tool.uv.sources]
tiders-core = { path = "../tiders-core/python", editable = true }
cd tiders
uv sync
Tiders Overview (Python SDK)
The tiders Python package is the primary user-facing interface for building blockchain data pipelines.
Two ways to use tiders
| Mode | How | When to use |
|---|---|---|
| Python SDK | Write a Python script, import tiders | Full control, custom logic, complex pipelines |
| CLI (No-Code) | Write a YAML config, run tiders start | Quick setup, no Python required, standard pipelines |
Both modes share the same pipeline engine. The CLI parses a YAML config into the same Python objects and calls the same run_pipeline() function.
Installation
pip install tiders tiders-core
For the CLI (no-code mode):
pip install "tiders[cli]"
Core Concepts
A pipeline is built from four components:
| Component | Description |
|---|---|
ProviderConfig | Data source (HyperSync, SQD, or RPC) |
Query | What data to fetch (block range, filters, field selection) |
Step | Transformations to apply (decode, cast, encode, custom) |
Writer | Output destination (DuckDB, ClickHouse, Iceberg, DeltaLake, Parquet) |
Basic Usage
Python
import asyncio
from tiders import config as cc, run_pipeline
from tiders_core import ingest
pipeline = cc.Pipeline(
provider=ingest.ProviderConfig(kind=ingest.ProviderKind.HYPERSYNC, url="https://eth.hypersync.xyz"),
query=query, # see Query docs
writer=writer, # see Writers docs
steps=[...], # see Steps docs
)
asyncio.run(run_pipeline(pipeline=pipeline))
yaml
provider:
kind: hypersync
url: ${PROVIDER_URL}
writer:
kind: duckdb
config:
path: data/output.duckdb
query:
kind: evm
from_block: 18000000
steps: [...]
tiders start config.yaml
Module Structure
tiders
├── config # Pipeline, Step, Writer configuration classes
├── pipeline # run_pipeline() entry point
├── cli/ # CLI entry point and YAML parser
├── writers/ # Output adapters (DuckDB, ClickHouse, Iceberg, etc.)
└── utils # Utility functions
Performance Model
tiders parallelizes three phases automatically:
- Ingestion — fetching data from the provider (async, concurrent)
- Processing — running transformation steps on each batch
- Writing — inserting into the output store
The next batch is being fetched while the current batch is being processed and the previous batch is being written.
CLI Overview (No-Code Mode)
The tiders CLI lets you run a complete blockchain data pipeline from a single YAML config file — no Python required.
tiders start config.yaml
How it works
The CLI maps 1:1 to the Python SDK — it parses the YAML into the same Python objects and calls the same run_pipeline() function:
- Parse — load the YAML file and substitute
${ENV_VAR}placeholders - Build — construct
ProviderConfig,Query,Steps, andWriterfrom the config sections - Run — call
run_pipeline(), identical to Python-mode execution
Commands
tiders start
Run a pipeline from a YAML config file.
tiders start [CONFIG_PATH] [OPTIONS]
Arguments:
CONFIG_PATH Path to the YAML config file (optional, default to use the YAML files in the folder)
Options:
--from-block INTEGER Override the starting block number from the config
--to-block INTEGER Override the ending block number from the config
--env-file PATH Path to a .env file (overrides default discovery)
--help Show this message and exit
--version Show the tiders version and exit
tiders codegen
Generate a standalone Python script from a YAML config file. The generated script constructs and runs the same pipeline using the tiders Python SDK — useful as a starting point when you need to customize beyond what YAML supports.
tiders codegen [CONFIG_PATH] [OPTIONS]
Arguments:
CONFIG_PATH Path to the YAML config file (optional, same discovery rules as start)
Options:
-o, --output PATH Output file path (defaults to <ProjectName>.py in the current directory)
--env-file PATH Path to a .env file (overrides default discovery)
--help Show this message and exit
The output filename is derived from the project.name field in the YAML, converted to snake_case (e.g. ERC20 Transfers becomes erc20_transfers.py).
Environment variables referenced in the YAML (e.g. ${PROVIDER_URL}) are emitted as os.environ.get("PROVIDER_URL") calls in the generated script, so secrets stay out of the code.
tiders abi
Fetch contract ABIs from Sourcify or Etherscan and save them as JSON files.
tiders abi [OPTIONS]
Options:
--address TEXT Contract address (single-address mode)
--chain-id TEXT Chain ID or name (default: 1). See supported chains below
--yaml-path PATH Path to YAML file with contract declarations
-o, --output PATH Output path. Single-address mode: file path. YAML mode: directory
--source [sourcify|etherscan] ABI source to try first (default: sourcify). Falls back to the other
--env-file PATH Path to a .env file (overrides default discovery)
--help Show this message and exit
Usage modes
1. Single address — fetch one ABI by contract address:
tiders abi --address 0xae78736Cd615f374D3085123A210448E74Fc6393
tiders abi --address 0xae78736Cd615f374D3085123A210448E74Fc6393 --chain-id base
2. From YAML file — fetch ABIs for all contracts declared in the YAML:
tiders abi --yaml-path pipeline.yaml #(optional, autodiscobery in current directory)
The --chain-id option in CLI or in the YAML config accept either a numeric chain ID or a chain name in some chains:
| Name | Chain ID |
|---|---|
ethereum, mainnet, ethereum-mainnet | 1 |
bnb | 56 |
base | 8453 |
arbitrum | 42161 |
polygon | 137 |
scroll | 534352 |
unichain | 130 |
Set ETHERSCAN_API_KEY in your environment or via .env file. Etherscan is skipped with a warning if not set.
Environment variables
Secrets and dynamic values are kept out of the YAML using ${VAR} placeholders:
provider:
kind: hypersync
url: ${PROVIDER_URL}
bearer_token: ${HYPERSYNC_BEARER_TOKEN}
The CLI automatically loads a .env file from the same directory as the config file before substitution. Use --env-file to point to a different location:
tiders start --env-file /path/to/.env config.yaml
An error is raised if any ${VAR} placeholder remains unresolved after substitution.
See the CLI YAML Reference for full details on all sections.
CLI YAML Reference
A tiders YAML config has seven top-level sections:
project: # pipeline metadata (required)
provider: # data source (required)
contracts: # ABI + address helpers (optional)
writer: # where to write output (required)
checkpoint: # resume from last written block (optional)
query: # what data to fetch (required)
steps: # transformation pipeline (optional)
table_aliases: # rename default table names (optional)
project
project:
name: my_pipeline # project name
description: My description. # project description
repository: https://github.com/yulesa/tiders # optional — informative only
environment_path: "../../.env" # optional — allows to override the .env file path
provider
provider:
kind: hypersync # hypersync | sqd | rpc
url: ${PROVIDER_URL}
bearer_token: ${TOKEN} # HyperSync only, optional
See Providers for full details.
contracts
Optional list of contracts. If a ABI path is defined, Tiders reads the events and functions signatures. Addresses, signatures, topic0 and ABI-derived values can be referenced by name anywhere in provider: or query:.
contracts:
- name: MyToken
address: "0xabc123..."
abi: ./MyToken.abi.json
chain_id: ethereum # numeric chain ID or a chain name for some chains
Reference syntax:
| Reference | Resolves to |
|---|---|
MyToken.address | The contract address string |
MyToken.Events.Transfer.topic0 | Keccak-256 hash of the event signature |
MyToken.Events.Transfer.signature | Full event signature string |
MyToken.Functions.transfer.selector | 4-byte function selector |
MyToken.Functions.transfer.signature | Full function signature string |
writer
See Writers for full details.
writer accepts either a single writer mapping or a list of writer mappings to write to multiple backends in parallel:
writer:
- kind: duckdb
config:
path: data/output.duckdb
- kind: csv
config:
base_dir: data/output
DuckDB
writer:
kind: duckdb
config:
path: data/output.duckdb # path to create or connect to a duckdb database
ClickHouse
writer:
kind: clickhouse
config:
host: localhost # ClickHouse server hostname
port: 8123 # ClickHouse HTTP port
username: default # ClickHouse username
password: ${CH_PASSWORD} # ClickHouse password
database: default # ClickHouse database name
secure: false # optional — use TLS, default: false
codec: LZ4 # optional — default compression codec for all columns
order_by: # optional — per-table ORDER BY columns
transfers: [block_number, log_index]
engine: MergeTree() # optional — ClickHouse table engine, default: MergeTree()
anchor_table: transfers # optional — table written last, for ordering guarantees
create_tables: true # optional — auto-create tables on first insert, default: true
Delta Lake
writer:
kind: delta_lake
config:
data_uri: s3://my-bucket/delta/ # base URI where Delta tables are stored
partition_by: [block_number] # optional — columns used for partitioning
storage_options: # optional — cloud storage credentials/options
AWS_REGION: us-east-1
AWS_ACCESS_KEY_ID: ${AWS_KEY}
anchor_table: transfers # optional — table written last, for ordering guarantees
Iceberg
writer:
kind: iceberg
config:
namespace: my_namespace # Iceberg namespace (database) to write tables into
catalog_uri: sqlite:///catalog.db # URI for the Iceberg catalog (e.g. sqlite or jdbc)
warehouse: s3://my-bucket/iceberg/ # warehouse root URI for the catalog
catalog_type: sql # catalog type (e.g. sql, rest, hive)
write_location: s3://my-bucket/iceberg/ # storage URI where Iceberg data files are written
PyArrow Dataset (Parquet)
writer:
kind: pyarrow_dataset
config:
base_dir: data/output # root directory for all output datasets
anchor_table: transfers # optional — table written last, for ordering guarantees
partitioning: [block_number] # optional — columns or Partitioning object per table
partitioning_flavor: hive # optional — partitioning flavor (e.g. hive)
max_rows_per_file: 1000000 # optional — max rows per output file, default: 0 (unlimited)
create_dir: true # optional — create output directory if missing, default: true
CSV
writer:
kind: csv
config:
base_dir: data/output # required — root directory for all output CSV files
delimiter: "," # optional, default: ","
include_header: true # optional, default: true
create_dir: true # optional — create output directory if missing, default: true
anchor_table: transfers # optional — table written last, for ordering guarantees
PostgreSQL
writer:
kind: postgresql
config:
host: localhost # required — PostgreSQL server hostname
dbname: postgres # optional, default: postgres
port: 5432 # optional, default: 5432
user: postgres # optional, default: postgres
password: ${PG_PASSWORD} # optional, default: postgres
schema: public # optional — PostgreSQL schema (namespace), default: public
create_tables: true # optional — auto-create tables on first push, default: true
anchor_table: transfers # optional — table written last, for ordering guarantees
checkpoint
The checkpoint tells the pipeline where to resume from after an interruption. At startup, tiders reads MAX(column) from table using the configured writer and sets query.from_block to that value plus one. If the table is empty or does not exist, from_block is left unchanged.
checkpoint:
table: transfers # required — table to read the max block from
column: block_number # optional — block-number column, default: "block_number"
writer_index: 0 # optional — index into the writers list, default: 0
| Field | Type | Default | Description |
|---|---|---|---|
table | string | — | Name of the destination table to query |
column | string | "block_number" | Column holding the block number |
writer_index | int | 0 | Index of the writer to read from (for multi-writer pipelines) |
query
The query defines what blockchain data to fetch: the block range, which tables to include, what filters to apply, and which fields to select.
See Query for full details on EVM and SVM query options, field selection, and request filters.
EVM
query:
kind: evm
from_block: 18000000
to_block: 18001000 # optional
include_all_blocks: false # optional
fields:
log: [address, topic0, topic1, topic2, topic3, data, block_number, transaction_hash, log_index]
block: [number, timestamp]
transaction: [hash, from, to, value]
trace: [action_from, action_to, action_value]
logs:
- topic0: "Transfer(address,address,uint256)" # signature or 0x hex
address: "0xabc..."
include_blocks: true
transactions:
- from: ["0xabc..."]
include_blocks: true
traces:
- action_from: ["0xabc..."]
SVM
query:
kind: svm
from_block: 330000000
to_block: 330001000
include_all_blocks: true
fields:
instruction: [block_slot, program_id, data, accounts]
transaction: [signature, fee]
block: [slot, timestamp]
instructions:
- program_id: ["JUP6LkbZbjS1jKKwapdHNy74zcZ3tLUZoi5QNyVTaV4"]
include_transactions: true
transactions:
- signer: ["0xabc..."]
logs:
- kind: [program, system_program]
balances:
- account: ["0xabc..."]
token_balances:
- mint: ["..."]
rewards:
- pubkey: ["..."]
steps
Steps are transformations applied to each batch of data before writing. They run in order and can decode, cast, encode, join, or apply custom logic.
See Steps for full details on each step kind.
evm_decode_events
Decode EVM log events using an ABI signature
- kind: evm_decode_events
config:
event_signature: "Transfer(address indexed from, address indexed to, uint256 amount)"
output_table: transfers # optional — name of the output table for decoded results, default: "decoded_logs"
input_table: logs # optional — name of the input table to decode, default: "logs"
allow_decode_fail: true # optional — when True rows that fails are nulls values instead of raising an error, default: False
filter_by_topic0: false # optional — when True only rows whose ``topic0`` matches the event topic0 are decoded, default: False
hstack: true # optional — when True decoded columns are horizontally stacked with the input columns, default: True
large_int_as_binary: false # optional — when True, int128/uint128/int256/uint256 are emitted as fixed-width big-endian Binary instead of Decimal, default: False
svm_decode_instructions
Decode Solana program instructions
- kind: svm_decode_instructions
config:
instruction_signature:
discriminator: "0xe517cb977ae3ad2a" # The instruction discriminator bytes used to identify the instruction type.
params: # The list of typed parameters to decode from the instruction data (after the discriminator).
- name: amount
type: u64
- name: data
type: { type: array, element: u8 }
accounts_names: [tokenAccountIn, tokenAccountOut] # Names assigned to positional accounts in the instruction.
allow_decode_fail: false # optional — when True, rows that fails are nulls values instead of raising an error, default: False
filter_by_discriminator: false # optional — when True, only rows whose data starting bytes matches the event topic0 are decoded, default: False
input_table: instructions # optional — name of the input table to decode, default: "instructions"
output_table: decoded_instructions # optional — name of the input table to decode, default: "decoded_instructions"
hstack: true # optional — when True, decoded columns are horizontally stacked with the input columns, default: True
svm_decode_logs
Decode Solana program logs
- kind: svm_decode_logs
config:
log_signature: # The list of typed parameters to decode from the log data.
params:
- name: amount_in
type: u64
- name: amount_out
type: u64
allow_decode_fail: false # optional — when True rows that fails are nulls values instead of raising an error, default: False
input_table: logs # optional — name of the input table to decode, default: "logs"
output_table: decoded_logs # optional — name of the input table to decode, default: "decoded_logs"
hstack: true # optional — when True decoded columns are horizontally stacked with the input columns, default: True
cast_by_type
- kind: cast_by_type
config:
from_type: "decimal256(76,0)" # The source pyarrow.DataType to match.
to_type: "decimal128(38,0)" # The target pyarrow.DataType to cast
allow_cast_fail: true # optional — when True, values that cannot be cast are set to null instead of raising an error, default: False
Supported type strings: int8–int64, uint8–uint64, float16–float64, string, utf8, large_string, binary, large_binary, bool, date32, date64, null, decimal128(p,s), decimal256(p,s).
cast
Cast all columns of one type to another
- kind: cast
config:
table_name: transfers # The name of the table whose columns should be cast.
mappings: # A mapping of column name to target pyarrow.DataType
amount: "decimal128(38,0)"
block_number: "int64"
allow_cast_fail: false # optional — When True, values that cannot be cast are set to null instead of raising an error, default: False
Supported type strings: int8–int64, uint8–uint64, float16–float64, string, utf8, large_string, binary, large_binary, bool, date32, date64, null, decimal128(p,s), decimal256(p,s).
hex_encode
Hex-encode all binary columns
- kind: hex_encode
config:
tables: [transfers] # optional — list of table names to process. When ``None``, all tables in the data dictionary are processed, default: None
prefixed: true # optional — When True, output strings are "0x"-prefixed, default: True
base58_encode
Base58-encode all binary columns
- kind: base58_encode
config:
tables: [instructions] # optional — list of table names to process. When ``None``, all tables in the data dictionary are processed, default: None
large_int_columns_to_binary
Convert named scale-0 Decimal128/Decimal256 columns in a single table to fixed-width big-endian binary (16 bytes and 32 bytes respectively). Produces the same byte layout as evm_decode_events with large_int_as_binary: true.
- kind: large_int_columns_to_binary
config:
table_name: transfers # required — table whose columns to convert
columns: # required — list of scale-0 Decimal columns to convert
- amount
- value
join_block_data
Join block fields into other tables (left outer join). Column collisions are prefixed with <block_table_name>_.
- kind: join_block_data
config:
tables: [logs] # optional — tables to join into; default: all tables except the block table
block_table_name: blocks # optional, default: "blocks"
join_left_on: [block_number] # optional, default: ["block_number"]
join_blocks_on: [number] # optional, default: ["number"]
join_evm_transaction_data
Join EVM transaction fields into other tables (left outer join). Column collisions are prefixed with <tx_table_name>_.
- kind: join_evm_transaction_data
config:
tables: [logs] # optional — tables to join into; default: all except the transactions table
tx_table_name: transactions # optional, default: "transactions"
join_left_on: [block_number, transaction_index] # optional, default: ["block_number", "transaction_index"]
join_transactions_on: [block_number, transaction_index] # optional, default: ["block_number", "transaction_index"]
join_svm_transaction_data
Join SVM transaction fields into other tables (left outer join). Column collisions are prefixed with <tx_table_name>_.
- kind: join_svm_transaction_data
config:
tables: [instructions] # optional — tables to join into; default: all except the transactions table
tx_table_name: transactions # optional, default: "transactions"
join_left_on: [block_slot, transaction_index] # optional, default: ["block_slot", "transaction_index"]
join_transactions_on: [block_slot, transaction_index] # optional, default: ["block_slot", "transaction_index"]
set_chain_id
Add a chain_id column
- kind: set_chain_id
config:
chain_id: 1 # The chain identifier to set (e.g. 1 for Ethereum mainnet).
delete_tables
Remove whole tables from the current pipeline data.
- kind: delete_tables
config:
tables:
- logs
- traces
delete_columns
Drop selected columns from one or more tables.
- kind: delete_columns
config:
tables:
transfers:
- raw_data
- topic3
rename_tables
Rename top-level tables in the current pipeline data.
- kind: rename_tables
config:
mappings:
decoded_logs: transfers # required
rename_columns
Rename columns in one or more tables.
- kind: rename_columns
config:
tables:
transfers:
from: sender
to: receiver
select_tables
Keep only the listed tables and drop the rest.
- kind: select_tables
config:
tables:
- transfers
- blocks
select_columns
Keep only the listed columns for each configured table.
- kind: select_columns
config:
tables:
transfers:
- block_number
- from
- to
- amount
reorder_columns
Move configured columns to the front of each table. Unlisted columns stay after them in their original order.
- kind: reorder_columns
config:
tables:
transfers:
- block_number
- transaction_index
- log_index
add_columns
Add constant-value columns to one or more tables. Existing columns with the same name are replaced.
- kind: add_columns
config:
tables:
transfers:
protocol: erc20
is_transfer: true
copy_columns
Copy existing columns to new names.
- kind: copy_columns
config:
tables:
transfers:
from: sender
to: receiver
prefix_columns
Add the same prefix to selected columns.
- kind: prefix_columns
config:
prefix: tx_ # required
tables:
transfers:
- hash
- from
- to
suffix_columns
Add the same suffix to selected columns.
- kind: suffix_columns
config:
suffix: _raw # required
tables:
transfers:
- data
- topic0
prefix_tables
Add the same prefix to selected table names.
- kind: prefix_tables
config:
prefix: raw_ # required
tables:
- logs
- transactions
suffix_tables
Add the same suffix to selected table names.
- kind: suffix_tables
config:
suffix: _decoded # required
tables:
- instructions
- logs
drop_empty_tables
Remove empty tables from the current pipeline data.
- kind: drop_empty_tables
config:
tables: # optional — when omitted, all tables are checked
- logs
- traces
This step also accepts an empty config to check every table:
- kind: drop_empty_tables
config: {}
sql
Run one or more DataFusion SQL queries. CREATE TABLE name AS SELECT ... stores results under name; plain SELECT stores as sql_result.
- kind: sql
config:
queries:
- >
CREATE TABLE enriched AS
SELECT t.*, b.timestamp
FROM transfers t
JOIN blocks b ON b.number = t.block_number
python_file
Load a custom step function from an external Python file. Paths are relative to the YAML config directory.
- kind: python_file
name: my_custom_step
config:
file: ./steps/my_step.py
function: transform # callable name in the file
step_type: datafusion # datafusion (default), polars, or pandas
context: # optional — passed as ctx to the function
threshold: 100
table_aliases
Rename the default ingestion table names.
EVM
table_aliases:
blocks: my_blocks # optional — name for the blocks response, default: "blocks"
transactions: my_txs # optional — name for the transactions response, default: "transactions"
logs: my_logs # optional — name for the logs response, default: "logs"
traces: my_traces # optional — name for the traces response, default: "traces"
SVM
table_aliases:
instructions: my_instructions # optional — name for the instructions response, default: "instructions"
transactions: my_txs # optional — name for the transactions response, default: "transactions"
logs: my_logs # optional — name for the logs response, default: "logs"
balances: my_balances # optional — name for the balances response, default: "balances"
token_balances: my_token_balances # optional — name for the token_balances response, default: "token_balances"
rewards: my_rewards # optional — name for the rewards response, default: "rewards"
blocks: my_blocks # optional — name for the blocks response, default: "blocks"
Providers
Providers are the data sources that tiders fetches blockchain data from. Each provider connects to a different backend service.
Choosing a Provider
- HyperSync — fast EVM historical data, allow request filtering; requires API key; Paid features
- SQD — fast, supports both EVM and SVM, allow request filtering; decentralized; Paid features
- RPC — works with traditional RPC, don’t allow request filtering; useful when other providers don’t support your chain
Unlike HyperSync and SQD, the RPC provider does not support server-side filtering of transactions or traces. That’s because RPC methods like eth_getBlockByNumber and trace_block return all data in a block with no filtering options. Setting TransactionRequest or TraceRequest with filtering fields (e.g. from_ =0xabc.., to=0xabc..., status=success) will produce an error.
Similarly, field selection does not improve performance with the RPC provider — all fields are always fetched from the node and unselected fields are dropped client-side.
Alternatively, you can ingest all data and filter post-indexing in your tiders pipeline or database instead. See the RPC querying docs for details.
Available Providers
| Provider | EVM (Ethereum) | SVM (Solana) | Description |
|---|---|---|---|
| HyperSync | Yes | No | High-performance indexed data |
| SQD | Yes | Yes | Decentralized data network |
| RPC | Yes | No | Any standard EVM JSON-RPC endpoint |
Configuration
All providers use ProviderConfig from tiders_core.ingest:
from tiders_core.ingest import ProviderConfig, ProviderKind
Common Parameters
These parameters are available for all providers:
| Parameter | Type | Default | Description |
|---|---|---|---|
kind | ProviderKind | — | Provider backend (hypersync, sqd, rpc) |
url | str | None | Provider endpoint URL. If None, uses the provider’s default |
bearer_token | str | None | Authentication token for protected APIs |
stop_on_head | bool | false | If true, stop when reaching the chain head; if false, keep polling indefinitely |
head_poll_interval_millis | int | None | How frequently (ms) to poll for new blocks when streaming live data |
buffer_size | int | None | Number of responses to buffer before sending to the consumer |
max_num_retries | int | None | Maximum number of retries for failed requests |
retry_backoff_ms | int | None | Delay increase between retries in milliseconds |
retry_base_ms | int | None | Base retry delay in milliseconds |
retry_ceiling_ms | int | None | Maximum retry delay in milliseconds |
req_timeout_millis | int | None | Request timeout in milliseconds |
RPC-only Parameters
| Parameter | Type | Default | Description |
|---|---|---|---|
batch_size | int | None | Number of blocks fetched per batch |
compute_units_per_second | int | None | Rate limit in compute units per second |
reorg_safe_distance | int | None | Number of blocks behind head considered safe from chain reorganizations |
trace_method | str | None | Trace API method: "trace_block" or "debug_trace_block_by_number" |
HyperSync
Python
provider = ProviderConfig(
kind=ProviderKind.HYPERSYNC,
url="https://eth.hypersync.xyz",
bearer_token = HYPERSYNC_TOKEN
)
yaml
provider:
kind: hypersync
url: ${PROVIDER_URL}
bearer_token: ${HYPERSYNC_BEARER_TOKEN} # optional
SQD
Python
provider = ProviderConfig(
kind=ProviderKind.SQD,
url="https://portal.sqd.dev/datasets/ethereum-mainnet",
)
yaml
provider:
kind: sqd
url: ${PROVIDER_URL}
RPC
Use any standard EVM JSON-RPC endpoint (Alchemy, Infura, QuickNode, local node, etc.):
Python
provider = ProviderConfig(
kind=ProviderKind.RPC,
url="https://eth-mainnet.g.alchemy.com/v2/YOUR_KEY",
)
yaml
provider:
kind: rpc
url: ${PROVIDER_URL}
stop_on_head: true # optional, default: false
trace_method: trace_block # optional — trace_block or debug_trace_block_by_number
The RPC provider uses tiders-rpc-client under the hood, which supports adaptive concurrency, retry logic, and streaming.
Contracts
Contracts is an optional module that makes it easier to get contract information, such as Events, Functions and their params.
When you define a contract, tiders parses the ABI JSON file and extracts all events and functions with their signatures, selectors, and topic hashes — so you don’t have to compute or hard-code them yourself.
Event/Functions Fields
Each event/function parsed from the ABI exposes:
| Field | Type | Description |
|---|---|---|
name | str | Event/Function name (e.g. "Swap") |
name_snake_case | str | Event/Function name in snake_case (e.g. "matched_orders") |
signature | str | Human-readable signature with types, names and indexed markers (events) (e.g. "Swap(address indexed sender, address indexed recipient, int256 amount0)") |
selector_signature | str | Canonical signature without names (e.g. "Swap(address,address,int256)") |
topic0 | str | (Event only) Keccak-256 hash of the selector signature, as 0x-prefixed hex |
selector | str | (Function-only) 4-byte function selector as 0x-prefixed hex |
YAML Usage
In YAML configs, define contracts under the contracts: key. Tiders automatically parses the ABI and makes all values available via reference syntax.
contracts:
- name: MyToken
address: "0xae78736Cd615f374D3085123A210448E74Fc6393"
abi: ./MyToken.abi.json # abi path
chain_id: ethereum # numeric chain ID or a chain name in some chains (used to download the ABI in the CLI command `tiders abi`)
Reference Syntax
Once a contract is defined, tiders parse will automatically extract ABI information, so you can reference its address, events, and functions by name anywhere in query: or steps: sections:
| Reference | Resolves to |
|---|---|
MyToken.address | The contract address string |
MyToken.Events.Transfer.name | Event name |
MyToken.Events.Transfer.topic0 | Keccak-256 hash of the event signature |
MyToken.Events.Transfer.signature | Full event signature string |
MyToken.Events.Transfer.name_snake_case | Event name in snake_case |
MyToken.Events.Transfer.selector_signature | Canonical event signature without names |
MyToken.Functions.transfer.selector | 4-byte function selector |
MyToken.Functions.transfer.signature | Full function signature string |
MyToken.Functions.transfer.name_snake_case | Function name in snake_case |
MyToken.Functions.transfer.selector_signature | Canonical function signature without names |
Python Usage
Use evm_abi_events and evm_abi_functions from tiders_core. These functions take a JSON ABI string and return a list[EvmAbiEvent] / list[EvmAbiFunction] with the fields described above.
from pathlib import Path
from tiders_core import evm_abi_events, evm_abi_functions
# Contract address
my_token_address = "0xae78736Cd615f374D3085123A210448E74Fc6393"
# Load ABI
abi_path = Path("./MyToken.abi.json")
abi_json = abi_path.read_text()
# Parse events — dict keyed by event name
events = {
ev.name: {
"topic0": ev.topic0,
"signature": ev.signature,
"name_snake_case": ev.name_snake_case,
"selector_signature": ev.selector_signature,
}
for ev in evm_abi_events(abi_json)
}
# Parse functions — dict keyed by function name
functions = {
fn.name: {
"selector": fn.selector,
"signature": fn.signature,
"name_snake_case": fn.name_snake_case,
"selector_signature": fn.selector_signature,
}
for fn in evm_abi_functions(abi_json)
}
You can then use the parsed values in your query and steps:
query = Query(
kind=QueryKind.EVM,
params=evm.Query(
from_block=18_000_000,
logs=[
evm.LogRequest(
address=[my_token_address],
topic0=[events["Transfer"]["topic0"]],
),
],
),
)
steps = [
Step(
kind=StepKind.EVM_DECODE_EVENTS,
config=EvmDecodeEventsConfig(
event_signature=events["Transfer"]["signature"],
),
),
]
Query
The query defines what blockchain data to fetch: the block range, which tables to include, what filters to apply, and which fields to select. Queries are specific to a blockchain type (Kind), and can be either:
- EVM (for Ethereum and compatible chains) or
- SVM (for Solana).
Each query consists of a request to select subsets of tables/data (block, logs, instructions) and field selectors to specify what columns should be included in the response for each table.
Structure
from tiders_core.ingest import Query, QueryKind
A query has:
kind—QueryKind.EVMorQueryKind.SVMparams— chain-specific query parameters
EVM Queries
Python
from tiders_core.ingest import evm
query = Query(
kind=QueryKind.EVM,
params=evm.Query(
from_block=18_000_000, # required
to_block=18_001_000, # optional — defaults to chain head
include_all_blocks=False, # optional — include blocks with no matching data
logs=[evm.LogRequest(...)], # optional — log filters
transactions=[evm.TransactionRequest(...)], # optional — transaction filters
traces=[evm.TraceRequest(...)], # optional — trace filters
fields=evm.Fields(...), # field selection
),
)
yaml
query:
kind: evm
from_block: 18000000
to_block: 18001000 # optional — defaults to chain head
include_all_blocks: false # optional — default: false
logs: [...]
transactions: [...]
traces: [...]
fields: {...}
EVM Table filters
The logs, transactionsand traces params enable fine-grained row filtering through [table]Request objects. Each request individually filters for a subset of rows in the tables. You can combine multiple requests to build complex queries tailored to your needs. Except for blocks, table selection is made through explicit inclusion in a dedicated request or an include_[table] parameter.
Log Requests
Filter event logs by contract address and/or topic. All filter fields are combined with OR logic within a field and AND logic across fields.
Python
evm.LogRequest(
address=["0xabc..."], # optional — list of log emitter addresses
topic0=["0xabc..."], # optional — list of keccak256 hash or event signature
topic1=["0xabc..."], # optional — list of first indexed parameter
topic2=["0xabc..."], # optional — list of second indexed parameter
topic3=["0xabc..."], # optional — list of third indexed parameter
include_transactions=False, # optional — include parent transaction
include_transaction_logs=False, # optional — include all logs from matching txs
include_transaction_traces=False, # optional — include traces from matching txs
include_blocks=True, # optional — include block data
)
yaml
query:
kind: evm
logs:
- address: "0xdabc..." # optional
topic0: "Transfer(address,address,uint256)" # optional — signature or 0x hex hash
topic1: "0xabc..." # optional
topic2: "0xabc..." # optional
topic3: "0xabc..." # optional
include_transactions: false # optional, default: false
include_transaction_logs: false # optional, default: false
include_transaction_traces: false # optional, default: false
include_blocks: true # optional, default: false
Transaction Requests
Filter transactions by sender, recipient, function selector, or other fields. Filtering transaction data at the source in a request is not supported by standart ETH JSON-RPC calls of RPC providers.
All filter fields are combined with OR logic within a field and AND logic across fields.
Python
evm.TransactionRequest(
from_=["0xabc..."], # optional — list of sender addresses
to=["0xabc..."], # optional — list of recipient addresses
sighash=["0xa9059cbb"], # optional — list of 4-byte function selectors (hex)
status=[1], # optional — list of status, 1=success, 0=failure
type_=[2], # optional — list of type, 0=legacy, 1=access list, 2=EIP-1559
contract_deployment_address=["0x..."],# optional — list of deployed contract addresses
hash=["0xabc..."], # optional — list of specific transaction hashes
include_logs=False, # optional — include emitted logs
include_traces=False, # optional — include execution traces
include_blocks=False, # optional — include block data
)
yaml
query:
kind: evm
transactions:
- from: ["0xabc..."] # optional
to: ["0xabc..."] # optional
sighash: ["0xa9059cbb"] # optional
status: [1] # optional
type: [2] # optional
contract_deployment_address: ["0x..."] # optional
hash: ["0xabc..."] # optional
include_logs: false # optional, default: false
include_traces: false # optional, default: false
include_blocks: false # optional, default: false
Trace Requests
Filter execution traces (internal transactions). Filtering trace data at the source in a request is not supported by standart ETH JSON-RPC calls of RPC providers.
All filter fields are combined with OR logic within a field and AND logic across fields.
Python
evm.TraceRequest(
from_=["0xabc..."], # optional — list of caller addresses
to=["0xabc..."], # optional — list of callee addresses
address=["0xabc..."], # optional — list of ontract addresses in the trace
call_type=["call"], # optional — list of call types, "call", "delegatecall", "staticcall"
reward_type=["block"], # optional — list of reward_type, "block", "uncle"
type_=["call"], # optional — list of trace type, "call", "create", "suicide"
sighash=["0xa9059cbb"], # optional — list of 4-byte function selectors
author=["0xabc..."], # optional — list of block reward author addresses
include_transactions=False, # optional — include parent transaction
include_transaction_logs=False, # optional — include logs from matching txs
include_transaction_traces=False, # optional — include all traces from matching txs
include_blocks=False, # optional — include block data
)
yaml
query:
kind: evm
traces:
- from: ["0xabc..."] # optional
to: ["0xabc..."] # optional
address: ["0xabc..."] # optional
call_type: ["call"] # optional — call, delegatecall, staticcall
reward_type: ["block"] # optional — block, uncle
type: ["call"] # optional — call, create, suicide
sighash: ["0xa9059cbb"] # optional
author: ["0xabc..."] # optional
include_transactions: false # optional, default: false
include_transaction_logs: false # optional, default: false
include_transaction_traces: false # optional, default: false
include_blocks: false # optional, default: false
EVM Field Selection
Select only the columns you need. All fields default to false.
Python
evm.Fields(
block=evm.BlockFields(number=True, timestamp=True, hash=True),
transaction=evm.TransactionFields(hash=True, from_=True, to=True, value=True),
log=evm.LogFields(block_number=True, address=True, topic0=True, data=True),
trace=evm.TraceFields(from_=True, to=True, value=True, call_type=True),
)
yaml
query:
kind: evm
fields:
block: [number, timestamp, hash]
transaction: [hash, from, to, value]
log: [block_number, address, topic0, data]
trace: [from, to, value, call_type]
Available Block Fields
number, hash, parent_hash, nonce, sha3_uncles, logs_bloom, transactions_root, state_root, receipts_root, miner, difficulty, total_difficulty, extra_data, size, gas_limit, gas_used, timestamp, uncles, base_fee_per_gas, blob_gas_used, excess_blob_gas, parent_beacon_block_root, withdrawals_root, withdrawals, l1_block_number, send_count, send_root, mix_hash
Available Transaction Fields
block_hash, block_number, from, gas, gas_price, hash, input, nonce, to, transaction_index, value, v, r, s, max_priority_fee_per_gas, max_fee_per_gas, chain_id, cumulative_gas_used, effective_gas_price, gas_used, contract_address, logs_bloom, type, root, status, sighash, y_parity, access_list, l1_fee, l1_gas_price, l1_fee_scalar, gas_used_for_l1, max_fee_per_blob_gas, blob_versioned_hashes, deposit_nonce, blob_gas_price, deposit_receipt_version, blob_gas_used, l1_base_fee_scalar, l1_blob_base_fee, l1_blob_base_fee_scalar, l1_block_number, mint, source_hash
Available Log Fields
removed, log_index, transaction_index, transaction_hash, block_hash, block_number, address, data, topic0, topic1, topic2, topic3
Available Trace Fields
from, to, call_type, gas, input, init, value, author, reward_type, block_hash, block_number, address, code, gas_used, output, subtraces, trace_address, transaction_hash, transaction_position, type, error, sighash, action_address, balance, refund_address
SVM Queries
Python
from tiders_core.ingest import svm
query = Query(
kind=QueryKind.SVM,
params=svm.Query(
from_block=330_000_000,
to_block=330_001_000, # optional — defaults to chain head
include_all_blocks=False, # optional — include blocks with no matching data
instructions=[svm.InstructionRequest(...)], # optional
transactions=[svm.TransactionRequest(...)], # optional
logs=[svm.LogRequest(...)], # optional
balances=[svm.BalanceRequest(...)], # optional
token_balances=[svm.TokenBalanceRequest(...)], # optional
rewards=[svm.RewardRequest(...)], # optional
fields=svm.Fields(...),
),
)
yaml
query:
kind: svm
from_block: 330000000
to_block: 330001000 # optional — defaults to chain head
include_all_blocks: false # optional — default: false
instructions: [...]
transactions: [...]
logs: [...]
balances: [...]
token_balances: [...]
rewards: [...]
fields: {...}
SVM Table filters
The instructions, transactions, logs, balances , token_balances, rewards and fields params enable fine-grained row filtering through [table]Request objects. Each request individually filters for a subset of rows in the tables. You can combine multiple requests to build complex queries tailored to your needs. Except for blocks, table selection is made through explicit inclusion in a dedicated request or an include_[table] parameter.
Instruction Requests
Filter Solana instructions by program, discriminator, or account. Discriminator and account filters (d1–d8, a0–a9) use OR logic within a field and AND logic across fields.
Python
svm.InstructionRequest(
program_id=["JUP6LkbZbjS1jKKwapdHNy74zcZ3tLUZoi5QNyVTaV4"], # optional — list of program ids, base58
discriminator=["0xe445a52e51cb9a1d40c6cde8260871e2"], # optional — list of discriminators, bytes or hex
d1=["0xe4"], # optional — list of 1-byte data prefix filter
d2=["0xe445"], # optional — list of 2-byte data prefix filter
d4=["0xe445a52e"], # optional — list of 4-byte data prefix filter
d8=["0xe445a52e51cb9a1d"], # optional — list of 8-byte data prefix filter
a0=["0xabc..."], # optional — list of account at index 0 (base58)
a1=["0xabc..."], # optional — list of account at index 1
# a2–a9 follow the same pattern
is_committed=False, # optional — only committed instructions
include_transactions=True, # optional — include parent transaction
include_transaction_token_balances=False, # optional — include token balance changes
include_logs=False, # optional — include program logs
include_inner_instructions=False, # optional — include inner (CPI) instructions
include_blocks=True, # optional — default: true
)
yaml
query:
kind: svm
instructions:
- program_id: ["JUP6LkbZbjS1jKKwapdHNy74zcZ3tLUZoi5QNyVTaV4"] # optional
discriminator: ["0xe445a52e51cb9a1d40c6cde8260871e2"] # optional
d1: ["0xe4"] # optional
d2: ["0xe445"] # optional
d4: ["0xe445a52e"] # optional
d8: ["0xe445a52e51cb9a1d"] # optional
a0: ["TokenkegQfeZyiNwAJbNbGKPFXCWuBvf9Ss623VQ5DA"] # optional
is_committed: false # optional, default: false
include_transactions: true # optional, default: false
include_transaction_token_balances: false # optional, default: false
include_logs: false # optional, default: false
include_inner_instructions: false # optional, default: false
include_blocks: true # optional, default: true
Transaction Requests (SVM)
Filter Solana transactions by fee payer.
Python
svm.TransactionRequest(
fee_payer=["0xabc..."], # optional — list of fee payer public keys (base58)
include_instructions=False, # optional — include all instructions
include_logs=False, # optional — include program logs
include_blocks=False, # optional — include block data
)
yaml
query:
kind: svm
transactions:
- fee_payer: ["0xabc..."] # optional
include_instructions: false # optional, default: false
include_logs: false # optional, default: false
include_blocks: false # optional, default: false
Log Requests (SVM)
Filter Solana program log messages by program ID and/or log kind.
Python
svm.LogRequest(
program_id=["JUP6LkbZbjS1jKKwapdHNy74zcZ3tLUZoi5QNyVTaV4"], # optional — list of program ids
kind=[svm.LogKind.LOG], # optional — list of kinds, log, data, other
include_transactions=False, # optional — include parent transaction
include_instructions=False, # optional — include the emitting instruction
include_blocks=False, # optional — include block data
)
yaml
query:
kind: svm
logs:
- program_id: ["JUP6LkbZbjS1jKKwapdHNy74zcZ3tLUZoi5QNyVTaV4"] # optional
kind: [log] # optional — log, data, other
include_transactions: false # optional, default: false
include_instructions: false # optional, default: false
include_blocks: false # optional, default: false
Balance Requests
Filter native SOL balance changes by account.
Python
svm.BalanceRequest(
account=["0xabc..."], # optional — list of account public keys (base58)
include_transactions=False, # optional — include parent transaction
include_transaction_instructions=False, # optional — include transaction instructions
include_blocks=False, # optional — include block data
)
yaml
query:
kind: svm
balances:
- account: ["0xabc..."] # optional — list of accounts
include_transactions: false # optional, default: false
include_transaction_instructions: false # optional, default: false
include_blocks: false # optional, default: false
Token Balance Requests
Filter SPL token balance changes. Pre/post filters match the state before and after the transaction.
Python
svm.TokenBalanceRequest(
account=["0xabc..."], # optional — list of token account public keys (base58)
pre_program_id=["TokenkegQ..."], # optional — list of token program ID before tx
post_program_id=["TokenkegQ..."], # optional — list of token program ID after tx
pre_mint=["0xabc..."], # optional — list of token mint address before tx
post_mint=["0xabc..."], # optional — list of token mint address after tx
pre_owner=["0xabc..."], # optional — list of token account owner before tx
post_owner=["0xabc..."], # optional — list of token account owner after tx
include_transactions=False, # optional — include parent transaction
include_transaction_instructions=False, # optional — include transaction instructions
include_blocks=False, # optional — include block data
)
yaml
query:
kind: svm
token_balances:
- account: ["0xabc..."] # optional
pre_mint: ["0xabc..."] # optional
post_mint: ["0xabc..."] # optional
pre_owner: ["0xabc..."] # optional
post_owner: ["0xabc..."] # optional
pre_program_id: ["TokenkegQ..."] # optional
post_program_id: ["TokenkegQ..."] # optional
include_transactions: false # optional, default: false
include_transaction_instructions: false # optional, default: false
include_blocks: false # optional, default: false
Reward Requests
Filter Solana validator reward records by public key.
Python
svm.RewardRequest(
pubkey=["0xabc..."], # optional — list of validator public keys (base58)
include_blocks=False, # optional — include block data
)
yaml
query:
kind: svm
rewards:
- pubkey: ["0xabc..."] # optional
include_blocks: false # optional, default: false
SVM Field Selection
Select only the columns you need. All fields default to false.
Python
svm.Fields(
instruction=svm.InstructionFields(block_slot=True, program_id=True, data=True),
transaction=svm.TransactionFields(signature=True, fee=True),
log=svm.LogFields(program_id=True, message=True),
balance=svm.BalanceFields(account=True, pre=True, post=True),
token_balance=svm.TokenBalanceFields(account=True, post_mint=True, post_amount=True),
reward=svm.RewardFields(pubkey=True, lamports=True, reward_type=True),
block=svm.BlockFields(slot=True, hash=True, timestamp=True),
)
yaml
query:
kind: svm
fields:
instruction: [block_slot, program_id, data]
transaction: [signature, fee]
log: [program_id, message]
balance: [account, pre, post]
token_balance: [account, post_mint, post_amount]
reward: [pubkey, lamports, reward_type]
block: [slot, hash, timestamp]
Available Instruction Fields
block_slot, block_hash, transaction_index, instruction_address, program_id, a0–a9, rest_of_accounts, data, d1, d2, d4, d8, error, compute_units_consumed, is_committed, has_dropped_log_messages
Available Transaction Fields (SVM)
block_slot, block_hash, transaction_index, signature, version, account_keys, address_table_lookups, num_readonly_signed_accounts, num_readonly_unsigned_accounts, num_required_signatures, recent_blockhash, signatures, err, fee, compute_units_consumed, loaded_readonly_addresses, loaded_writable_addresses, fee_payer, has_dropped_log_messages
Available Log Fields (SVM)
block_slot, block_hash, transaction_index, log_index, instruction_address, program_id, kind, message
Available Balance Fields
block_slot, block_hash, transaction_index, account, pre, post
Available Token Balance Fields
block_slot, block_hash, transaction_index, account, pre_mint, post_mint, pre_decimals, post_decimals, pre_program_id, post_program_id, pre_owner, post_owner, pre_amount, post_amount
Available Reward Fields
block_slot, block_hash, pubkey, lamports, post_balance, reward_type, commission
Available Block Fields (SVM)
slot, hash, parent_slot, parent_hash, height, timestamp
Transformation Steps
Transformation steps are built-in processing operations that are applied sequentially during pipeline execution. They run in order and can decode, cast, encode, join, or apply custom logic.
Here’s an overview of how transformation steps work:
- Select Step: Each transformation step defines a series of operations. This can range from data validation, decoding, encoding, and joining data, to custom transformations.
- Step Configuration: Each step has a configuration object that defines input parameters and/or modifies behavior. For example,
EvmDecodeEventsConfigrequires anevent_signatureand has configs for horizontally stacking raw and decoded columns, not stopping on failed rows, and naming the output table. - Process Flow: Steps are executed in the order they are provided. After each step, the data is updated, and the transformed data is passed to the next step in the pipeline.
Built-in Steps
| Step | yaml | Description |
|---|---|---|
EVM_DECODE_EVENTS | evm_decode_events | Decode EVM log events using an ABI signature |
SVM_DECODE_INSTRUCTIONS | svm_decode_instructions | Decode Solana program instructions |
SVM_DECODE_LOGS | svm_decode_logs | Decode Solana program logs |
CAST | cast | Cast specific columns to new types |
CAST_BY_TYPE | cast_by_type | Cast all columns of one Arrow type to another |
HEX_ENCODE | hex_encode | Hex-encode all binary columns |
BASE58_ENCODE | base58_encode | Base58-encode all binary columns |
U256_TO_BINARY | u256_to_binary | Convert U256 decimal columns to binary |
LARGE_INT_COLUMNS_TO_BINARY | large_int_columns_to_binary | Convert named large-integer columns in one table to fixed-width binary |
SET_CHAIN_ID | set_chain_id | Add a constant chain_id column to all tables |
DELETE_TABLES | delete_tables | Remove tables from the current pipeline data |
DELETE_COLUMNS | delete_columns | Drop columns from one or more tables |
RENAME_TABLES | rename_tables | Rename tables in the current pipeline data |
RENAME_COLUMNS | rename_columns | Rename columns in one or more tables |
SELECT_TABLES | select_tables | Keep only selected tables |
SELECT_COLUMNS | select_columns | Keep only selected columns in configured tables |
REORDER_COLUMNS | reorder_columns | Move selected columns to the front of configured tables |
ADD_COLUMNS | add_columns | Add or replace constant-value columns |
COPY_COLUMNS | copy_columns | Copy existing columns to new names |
PREFIX_COLUMNS | prefix_columns | Add a prefix to selected columns |
SUFFIX_COLUMNS | suffix_columns | Add a suffix to selected columns |
PREFIX_TABLES | prefix_tables | Add a prefix to selected table names |
SUFFIX_TABLES | suffix_tables | Add a suffix to selected table names |
DROP_EMPTY_TABLES | drop_empty_tables | Remove empty tables |
JOIN_BLOCK_DATA | join_block_data | Join block fields into other tables |
JOIN_EVM_TRANSACTION_DATA | join_evm_transaction_data | Join EVM transaction fields into other tables |
JOIN_SVM_TRANSACTION_DATA | join_svm_transaction_data | Join SVM transaction fields into other tables |
POLARS | — | Custom transformation using Polars DataFrames |
PANDAS | — | Custom transformation using Pandas DataFrames |
DATAFUSION | — | Custom transformation using DataFusion |
| — | python_file | Load a custom Polars or DataFusion function from a .py file (yaml only) |
| — | sql | Run DataFusion SQL queries (yaml only) |
EVM Decode Events
Decodes raw log data and topic fields into typed columns using an ABI event signature.
Python
cc.Step(
kind=cc.StepKind.EVM_DECODE_EVENTS,
config=cc.EvmDecodeEventsConfig(
event_signature="Transfer(address indexed from, address indexed to, uint256 amount)",
output_table="token_transfers", # optional — name of the output table for decoded results, default: "decoded_logs"
input_table="logs", # optional — name of the input table to decode, default: "logs"
allow_decode_fail=True, # optional — when True rows that fails are nulls values instead of raising an error, default: False
filter_by_topic0=False, # optional — when True only rows whose ``topic0`` matches the event topic0 are decoded, default: False
hstack=True, # optional — when True decoded columns are horizontally stacked with the input columns, default: True
large_int_as_binary=False, # optional — when True, int128/uint128/int256/uint256 are emitted as fixed-width big-endian Binary instead of Decimal, default: False
),
)
yaml
- kind: evm_decode_events
config:
event_signature: "Transfer(address indexed from, address indexed to, uint256 amount)"
output_table: transfers # optional, default: decoded_logs
input_table: logs # optional, default: logs
allow_decode_fail: false # optional, default: false
filter_by_topic0: false # optional, default: false
hstack: true # optional, default: true
large_int_as_binary: false # optional, default: false
SVM Decode Instructions
Decodes raw Solana instruction data into structured columns using an Anchor/Borsh instruction signature.
Python
from tiders_core.svm_decode import InstructionSignature
cc.Step(
kind=cc.StepKind.SVM_DECODE_INSTRUCTIONS,
config=cc.SvmDecodeInstructionsConfig(
instruction_signature=InstructionSignature(...),
output_table="decoded_instructions", # optional — name of the input table to decode, default: "decoded_instructions"
input_table="instructions", # optional — name of the input table to decode, default: "instructions"
allow_decode_fail=False, # optional — when True, rows that fails are nulls values instead of raising an error, default: False
filter_by_discriminator=False, # optional — when True, only rows whose data starting bytes matches the event topic0 are decoded, default: False
hstack=True, # optional — when True, decoded columns are horizontally stacked with the input columns, default: True
),
)
yaml
- kind: svm_decode_instructions
config:
instruction_signature: {...} # required
output_table: decoded_instructions # optional, default: "decoded_instructions"
input_table: instructions # optional, default: "instructions"
allow_decode_fail: false # optional, default: false
filter_by_discriminator: false # optional, default: false
hstack: true # optional, default: true
Instruction Signature
Signatures objects serve as decoding blueprints: they describe the expected structure of an instruction — including the name, type, and length of each parameter — allowing the pipeline to parse and interpret the raw byte data reliably.
Users can construct these signatures by gathering information from a variety of sources:
- Published IDLs (when available)
- Program source code (typically in Rust)
- Manual inspection of raw instructions on a Solana explorer
Here’s an example of an instruction signature for decoding Jupiter swap instructions. We’ll break down each part below:
instruction_signature = InstructionSignature(
discriminator="0xe445a52e51cb9a1d40c6cde8260871e2",
params=[
ParamInput(
name="Amm",
param_type=FixedArray(DynType.U8, 32),
),
ParamInput(
name="InputMint",
param_type=FixedArray(DynType.U8, 32),
),
ParamInput(
name="InputAmount",
param_type=DynType.U64,
),
ParamInput(
name="OutputMint",
param_type=FixedArray(DynType.U8, 32),
),
ParamInput(
name="OutputAmount",
param_type=DynType.U64,
),
],
accounts_names=[],
)
Discriminators
A discriminator is a fixed sequence of bytes at the beginning of serialized data that identifies which instruction, struct, or event the data represents. During decoding, the discriminator matches raw data to the correct signature definition.
Discriminators are one of the most challenging parts to reverse-engineer because Solana has no standard for defining them. Here are some common patterns observed in real-world programs:
- Sequential values: Some programs use simple, ordered values (e.g., 0x00, 0x01, 0x02, …) as discriminators.
- Anchor conventions: Anchor programs typically use the first 8 bytes of the SHA-256 hash of a struct name as the discriminator, ensuring uniqueness.
- Nested Anchor logs: Some Anchor-based programs use a two-level discriminator — the first 8 bytes identify a CPI log instruction, and the next 8 bytes identify a specific data structure inside the log (for a total of 16 bytes).
- Completely custom formats: Some programs define arbitrarily structured discriminators that don’t follow any public pattern.
If you can reliably identify a particular instruction from observed transactions, you may be able to deduce its discriminator by finding repeated byte sequences at the start of the instruction data.
Params
The params field in the signature defines the expected values within the instruction data — in the exact order they appear. Each param can include a name, a type, and in the case of composite types, a list of fields or variants. These parameters are ordered and interpreted sequentially during decoding.
Supported types include:
- Primitives: Uint, Int, and Bool
- Complex types:
- FixedArray: A fixed-length array of another type (e.g., Public keys, for example, are 32 bytes (or u8) [u8; 32].)
- Array: A dynamic-length array. Data are prefixed with a length indicator to determine how many elements to decode.
- Struct: A composite of keys - value types (like a dictionary)
- Enum: A type representing one of several variants. Variant may optionally carry its own nested value.
- Option: A nullable value that either holds a nested type or is empty.
All complex types can be nested arbitrarily — for example, an array of structs, an option of an enum, or a struct containing other structs.
Accounts Names
In Solana, each instruction includes a list of accounts it interacts with, passed as a separate data structure from the instruction data itself. The accounts_names field allows you to assign meaningful names to these account indices, making decoded output easier to read and analyze.
While the decoder doesn’t interpret account data contents, having named accounts helps clarify the role each address plays in the instruction (e.g., “user”, “token_account”, “vault”, etc.).
SVM Decode Logs
Decodes raw Solana program log entries into structured columns using a log signature definition. Logs signatures works the same way as instructions signatures.
Python
from tiders_core.svm_decode import LogSignature
cc.Step(
kind=cc.StepKind.SVM_DECODE_LOGS,
config=cc.SvmDecodeLogsConfig(
log_signature=LogSignature(...),
output_table="decoded_logs", # optional — when True rows that fails are nulls values instead of raising an error, default: False
input_table="logs", # optional — name of the input table to decode, default: "logs"
allow_decode_fail=False, # optional — when True rows that fails are nulls values instead of raising an error, default: False
hstack=True, # optional — when True decoded columns are horizontally stacked with the input columns, default: True
),
)
yaml
- kind: svm_decode_logs
config:
log_signature: {...} # required
output_table: decoded_logs # optional, optional, default: "decoded_logs"
input_table: logs # optional, optional, default: "logs"
allow_decode_fail: false # optional, optional, default: false
hstack: true # optional, optional, default: true
Cast
Casts specific columns in a table to new Arrow data types.
Python
import pyarrow as pa
cc.Step(
kind=cc.StepKind.CAST,
config=cc.CastConfig(
table_name="transfers", # required — the name of the table whose columns should be cast.
mappings={ # required — a mapping of column name to target pyarrow.DataType
"value": pa.decimal128(38, 0),
"block_number": pa.int64(),
},
allow_cast_fail=False, # optional — When True, values that cannot be cast are set to null instead of raising an error, default: False
),
)
yaml
- kind: cast
config:
table_name: transfers # required
mappings: # required — column name to Arrow type
value: "decimal128(38,0)"
block_number: int64
allow_cast_fail: false # optional, default: false
Supported type strings: int8–int64, uint8–uint64, float16–float64, string, binary, bool, date32, date64, null, decimal128(p,s), decimal256(p,s).
Cast By Type
Casts all columns of a given Arrow type to a different type, across every table.
Python
import pyarrow as pa
cc.Step(
kind=cc.StepKind.CAST_BY_TYPE,
config=cc.CastByTypeConfig(
from_type=pa.decimal256(76, 0),
to_type=pa.decimal128(38, 0),
allow_cast_fail=False, # default: false
),
)
yaml
- kind: cast_by_type
config:
from_type: "decimal256(76,0)" # required — the source pyarrow.DataType to match.
to_type: "decimal128(38,0)" # required — the target pyarrow.DataType to cast
allow_cast_fail: false # optional, default: false
Supported type strings: int8–int64, uint8–uint64, float16–float64, string, binary, bool, date32, date64, null, decimal128(p,s), decimal256(p,s).
Hex Encode
Converts all binary columns to hex-encoded strings for readability.
Python
cc.Step(
kind=cc.StepKind.HEX_ENCODE,
config=cc.HexEncodeConfig(
tables=["transfers"], # default: None — apply to all tables
prefixed=True, # default: true — add 0x prefix
),
)
yaml
- kind: hex_encode
config:
tables: [transfers] # optional — list of table names to process. When ``None``, all tables in the data dictionary are processed, default: None
prefixed: true # optional — When True, output strings are "0x"-prefixed, default: True
Base58 Encode
Converts all binary columns to Base58-encoded strings, used for Solana public keys and signatures.
Python
cc.Step(
kind=cc.StepKind.BASE58_ENCODE,
config=cc.Base58EncodeConfig(
tables=["instructions"], # optional — list of table names to process. When ``None``, all tables in the data dictionary are processed, default: None
),
)
yaml
- kind: base58_encode
config:
tables: [instructions] # optional — apply to specific tables only; default: all tables
Large Int Columns to Binary
Converts named scale-0 Decimal128 or Decimal256 columns in a single table to fixed-width big-endian two’s-complement binary (16 bytes for Decimal128, 32 bytes for Decimal256). Produces the same byte layout as evm_decode_events with large_int_as_binary=True, so the two approaches are interchangeable. Use this step when you want to convert specific columns after decoding rather than during it.
Python
cc.Step(
kind=cc.StepKind.LARGE_INT_COLUMNS_TO_BINARY,
config=cc.LargeIntColumnsToBinaryConfig(
table_name="transfers", # required — table whose columns to convert
columns=["amount", "value"], # required — list of scale-0 Decimal columns to convert
),
)
yaml
- kind: large_int_columns_to_binary
config:
table_name: transfers # required — table whose columns to convert
columns: # required — list of scale-0 Decimal columns to convert
- amount
- value
Join Block Data
Joins block fields into other tables using a left outer join. Column collisions are prefixed with <block_table_name>_.
Python
cc.Step(
kind=cc.StepKind.JOIN_BLOCK_DATA,
config=cc.JoinBlockDataConfig(
tables=["logs"], # optional — list of tables to join into; default: all tables except the block table
block_table_name="blocks", # optional — name of the blocks table, default: "blocks"
join_left_on=["block_number"], # optional — join key on the left (child) table, default: ["block_number"]
join_blocks_on=["number"], # optional — join key on the blocks table, default: ["number"]
),
)
yaml
- kind: join_block_data
config:
tables: [logs] # optional — tables to join into; default: all tables except the block table
block_table_name: blocks # optional, default: "blocks"
join_left_on: [block_number] # optional, default: ["block_number"]
join_blocks_on: [number] # optional, default: ["number"]
Join EVM Transaction Data
Joins EVM transaction fields into other tables using a left outer join. Column collisions are prefixed with <tx_table_name>_.
Python
cc.Step(
kind=cc.StepKind.JOIN_EVM_TRANSACTION_DATA,
config=cc.JoinEvmTransactionDataConfig(
tables=["logs"], # optional — list of tables to join into; default: all tables except the transactions table
tx_table_name="transactions", # optional — name of the transactions table, default: "transactions"
join_left_on=["block_number", "transaction_index"], # optional — join key on the left table, default: ["block_number", "transaction_index"]
join_transactions_on=["block_number", "transaction_index"],# optional — join key on the transactions table, default: ["block_number", "transaction_index"]
),
)
yaml
- kind: join_evm_transaction_data
config:
tables: [logs] # optional — tables to join into; default: all except the transactions table
tx_table_name: transactions # optional, default: "transactions"
join_left_on: [block_number, transaction_index] # optional, default: ["block_number", "transaction_index"]
join_transactions_on: [block_number, transaction_index] # optional, default: ["block_number", "transaction_index"]
Join SVM Transaction Data
Joins SVM transaction fields into other tables using a left outer join. Column collisions are prefixed with <tx_table_name>_.
Python
cc.Step(
kind=cc.StepKind.JOIN_SVM_TRANSACTION_DATA,
config=cc.JoinSvmTransactionDataConfig(
tables=["instructions"], # optional — list of tables to join into; default: all tables except the transactions table
tx_table_name="transactions", # optional — name of the transactions table, default: "transactions"
join_left_on=["block_slot", "transaction_index"], # optional — join key on the left table, default: ["block_slot", "transaction_index"]
join_transactions_on=["block_slot", "transaction_index"],# optional — join key on the transactions table, default: ["block_slot", "transaction_index"]
),
)
yaml
- kind: join_svm_transaction_data
config:
tables: [instructions] # optional — tables to join into; default: all except the transactions table
tx_table_name: transactions # optional, default: "transactions"
join_left_on: [block_slot, transaction_index] # optional, default: ["block_slot", "transaction_index"]
join_transactions_on: [block_slot, transaction_index] # optional, default: ["block_slot", "transaction_index"]
Set Chain ID
Adds (or replaces) a constant chain_id column on every table.
Python
cc.Step(
kind=cc.StepKind.SET_CHAIN_ID,
config=cc.SetChainIdConfig(
chain_id=1, # The chain identifier to set (e.g. 1 for Ethereum mainnet).
),
)
yaml
- kind: set_chain_id
config:
chain_id: 1 # required
Delete Tables
Removes whole tables from the current pipeline data before later steps or writers see them.
Python
cc.Step(
kind=cc.StepKind.DELETE_TABLES,
config=cc.DeleteTablesConfig(
tables=["logs", "traces"], # required
),
)
yaml
- kind: delete_tables
config:
tables:
- logs
- traces
Delete Columns
Drops selected columns from one or more tables.
Python
cc.Step(
kind=cc.StepKind.DELETE_COLUMNS,
config=cc.DeleteColumnsConfig(
tables={
"transfers": ["raw_data", "topic3"],
}, # required
),
)
yaml
- kind: delete_columns
config:
tables:
transfers:
- raw_data
- topic3
Rename Tables
Renames top-level tables in the current pipeline data.
Python
cc.Step(
kind=cc.StepKind.RENAME_TABLES,
config=cc.RenameTablesConfig(
mappings={
"decoded_logs": "transfers",
}, # required
),
)
yaml
- kind: rename_tables
config:
mappings:
decoded_logs: transfers # required
Rename Columns
Renames columns in one or more tables.
Python
cc.Step(
kind=cc.StepKind.RENAME_COLUMNS,
config=cc.RenameColumnsConfig(
tables={
"transfers": {
"from": "sender",
"to": "receiver",
},
}, # required
),
)
yaml
- kind: rename_columns
config:
tables:
transfers:
from: sender
to: receiver
Select Tables
Keeps only the listed tables and drops everything else.
Python
cc.Step(
kind=cc.StepKind.SELECT_TABLES,
config=cc.SelectTablesConfig(
tables=["transfers", "blocks"], # required
),
)
yaml
- kind: select_tables
config:
tables:
- transfers
- blocks
Select Columns
Keeps only the listed columns for each configured table.
Python
cc.Step(
kind=cc.StepKind.SELECT_COLUMNS,
config=cc.SelectColumnsConfig(
tables={
"transfers": ["block_number", "from", "to", "amount"],
}, # required
),
)
yaml
- kind: select_columns
config:
tables:
transfers:
- block_number
- from
- to
- amount
Reorder Columns
Moves configured columns to the front of each table. Any remaining columns stay after them in their original order.
Python
cc.Step(
kind=cc.StepKind.REORDER_COLUMNS,
config=cc.ReorderColumnsConfig(
tables={
"transfers": ["block_number", "transaction_index", "log_index"],
}, # required
),
)
yaml
- kind: reorder_columns
config:
tables:
transfers:
- block_number
- transaction_index
- log_index
Add Columns
Adds constant-value columns to one or more tables. If a target column already exists, it is replaced.
Python
cc.Step(
kind=cc.StepKind.ADD_COLUMNS,
config=cc.AddColumnsConfig(
tables={
"transfers": {
"protocol": "erc20",
"is_transfer": True,
},
}, # required
),
)
yaml
- kind: add_columns
config:
tables:
transfers:
protocol: erc20
is_transfer: true
Copy Columns
Copies existing columns to new names in one or more tables.
Python
cc.Step(
kind=cc.StepKind.COPY_COLUMNS,
config=cc.CopyColumnsConfig(
tables={
"transfers": {
"from": "sender",
"to": "receiver",
},
}, # required
),
)
yaml
- kind: copy_columns
config:
tables:
transfers:
from: sender
to: receiver
Prefix Columns
Prepends the same prefix to selected columns in each configured table.
Python
cc.Step(
kind=cc.StepKind.PREFIX_COLUMNS,
config=cc.PrefixColumnsConfig(
prefix="tx_",
tables={
"transfers": ["hash", "from", "to"],
}, # required
),
)
yaml
- kind: prefix_columns
config:
prefix: tx_ # required
tables:
transfers:
- hash
- from
- to
Suffix Columns
Appends the same suffix to selected columns in each configured table.
Python
cc.Step(
kind=cc.StepKind.SUFFIX_COLUMNS,
config=cc.SuffixColumnsConfig(
suffix="_raw",
tables={
"transfers": ["data", "topic0"],
}, # required
),
)
yaml
- kind: suffix_columns
config:
suffix: _raw # required
tables:
transfers:
- data
- topic0
Prefix Tables
Prepends the same prefix to selected table names.
Python
cc.Step(
kind=cc.StepKind.PREFIX_TABLES,
config=cc.PrefixTablesConfig(
prefix="raw_",
tables=["logs", "transactions"], # required
),
)
yaml
- kind: prefix_tables
config:
prefix: raw_ # required
tables:
- logs
- transactions
Suffix Tables
Appends the same suffix to selected table names.
Python
cc.Step(
kind=cc.StepKind.SUFFIX_TABLES,
config=cc.SuffixTablesConfig(
suffix="_decoded",
tables=["instructions", "logs"], # required
),
)
yaml
- kind: suffix_tables
config:
suffix: _decoded # required
tables:
- instructions
- logs
Drop Empty Tables
Removes empty tables from the current pipeline data. You can target specific table names or omit tables to check every table.
Python
cc.Step(
kind=cc.StepKind.DROP_EMPTY_TABLES,
config=cc.DropEmptyTablesConfig(
tables=["logs", "traces"], # optional — default: None (check all tables)
),
)
yaml
- kind: drop_empty_tables
config:
tables: # optional — default: all tables
- logs
- traces
You can also check every table by passing an empty config:
- kind: drop_empty_tables
config: {}
Custom Steps with Polars (Python only)
The Polars step lets you plug any Python function directly into the pipeline. When the step runs, tiders converts every in-memory PyArrow table into a polars.DataFrame, calls your function with all of them at once, and then converts the results back to PyArrow tables so the rest of the pipeline can continue.
Your function receives two arguments:
data— adict[str, pl.DataFrame]mapping table names (e.g."transfers","blocks") to their current Polars DataFrames.context— any value (a dict, scalar, list, etc.) passed viacontextin the config , it exports this varible from the pipeline to the callable python function. Useful for parameterizing the function without hard-coding values. It isNonewhen not set.
The function must return a dict[str, pl.DataFrame] mapping table name to tables. You can return the same tables with modifications, drop tables, or add new ones — whatever is in the returned dict becomes the new state of the pipeline’s data for subsequent steps.
Requires pip install tiders[polars].
import polars as pl
import tiders as cc
def my_transform(data: dict[str, pl.DataFrame], context) -> dict[str, pl.DataFrame]:
threshold = context["threshold"] if context else 0
transfers = data["transfers"]
# filter low-value transfers and add a normalized column
data["transfers"] = (
transfers
.filter(pl.col("value") > threshold)
.with_columns((pl.col("value") / 1e18).alias("value_eth"))
)
data.pop("raw_logs")
return data # returned data dict will include the original inputs tables, except "raw_logs" (popped) and the add (or updated) table "transfer"
cc.Step(
kind=cc.StepKind.POLARS,
config=cc.PolarsStepConfig(
runner=my_transform,
context={"threshold": 1_000_000}, # optional — variable passed as context to the function, in this case a dict.
),
)
Custom Steps with Pandas (Python only)
The Pandas step lets you plug any Python function directly into the pipeline. When the step runs, tiders converts every in-memory PyArrow table into a pandas.DataFrame, calls your function with all of them at once, and then converts the results back to PyArrow tables so the rest of the pipeline can continue.
Your function receives two arguments:
data— adict[str, pd.DataFrame]mapping table names (e.g."transfers","blocks") to their current Pandas DataFrames.context— any value (a dict, scalar, list, etc.) passed viacontextin the config, it exports this variable from the pipeline to the callable python function. Useful for parameterizing the function without hard-coding values. It isNonewhen not set.
The function must return a dict[str, pd.DataFrame] mapping table name to tables. You can return the same tables with modifications, drop tables, or add new ones — whatever is in the returned dict becomes the new state of the pipeline’s data for subsequent steps.
Requires pip install tiders[pandas].
import pandas as pd
import tiders as cc
def my_transform(data: dict[str, pd.DataFrame], context) -> dict[str, pd.DataFrame]:
threshold = context["threshold"] if context else 0
transfers = data["transfers"]
# filter low-value transfers and add a normalized column
transfers = transfers[transfers["value"] > threshold].copy()
transfers["value_eth"] = transfers["value"] / 1e18
data["transfers"] = transfers
data.pop("raw_logs")
return data # returned data dict will include the original inputs tables, except "raw_logs" (popped) and the added (or updated) table "transfers"
cc.Step(
kind=cc.StepKind.PANDAS,
config=cc.PandasStepConfig(
runner=my_transform,
context={"threshold": 1_000_000}, # optional — variable passed as context to the function, in this case a dict.
),
)
Custom Steps with DataFusion (Python only)
The DataFusion step uses Apache DataFusion as the execution engine, which lets you write SQL queries against the pipeline tables within your custom function.
When the step runs, tiders creates a fresh datafusion.SessionContext, registers every in-memory PyArrow table as a DataFusion DataFrame inside it, and calls your function. Your function can run SQL queries through session_ctx.sql(...), transform DataFrames using DataFusion’s DataFrame API, or combine both. The returned DataFrames are converted back to PyArrow tables for the next step.
Your function receives three arguments:
session_ctx— thedatafusion.SessionContextwith all current tables already registered by name, so you can query them directly with SQL.data— adict[str, datafusion.DataFrame]mapping table names to their DataFusion DataFrames. It’s a convenience shortcut for the DataFrame API — equivalent to callingsession_ctx.table(name)for each table and useful to construct the returning data.context— any value (a dict, scalar, list, etc.) passed viacontextin the config , it exports this varible from the pipeline to the callable python function. Useful for parameterizing the function without hard-coding values. It isNonewhen not set.
The function must return a dict[str, datafusion.DataFrame] mapping table name to tables. User is responsible to manage the returning dict. You can return the same tables with modifications, drop tables, or add new ones — whatever is in the returned dict becomes the new state of the pipeline’s data for subsequent steps.
Requires pip install tiders[datafusion].
import datafusion
import tiders as cc
def my_sql_transform(session_ctx, data, context):
min_block = context["min_block"] if context else 0
data["transfers"] = session_ctx.sql(f"""
SELECT t.*, b.timestamp
FROM transfers t
JOIN blocks b ON b.number = t.block_number
WHERE t.block_number >= {min_block}
""")
data.pop("raw_logs")
return data # returned data dict will include the original inputs tables, except "raw_logs" (popped) and the added (or updated) table "transfer"
cc.Step(
kind=cc.StepKind.DATAFUSION,
config=cc.DataFusionStepConfig(
runner=my_sql_transform,
context={"min_block": 18_500_000}, # optional — variable passed as context to the function, in this case a dict.
),
)
Python File (yaml only)
The python_file kind is the yaml equivalent of the Polars and DataFusion custom steps. It imports a .py file as a module, looks up the named function, and runs it as either a Polars or DataFusion step depending on step_type.
The file path is resolved relative to the yaml config file’s directory. The function must be defined at the module level (not nested inside another function or class).
Polars
Set step_type: polars. The function must use the (data, context) signature described in Custom Steps with Polars.
./steps/my_step.py:
import polars as pl
def my_transform(data: dict[str, pl.DataFrame], context) -> dict[str, pl.DataFrame]:
threshold = context["threshold"] if context else 0
transfers = data["transfers"]
transfers = (
transfers
.filter(pl.col("value") > threshold)
.with_columns((pl.col("value") / 1e18).alias("value_eth"))
)
data["transfers"] = transfers
return data
- kind: python_file
config:
file: ./steps/my_step.py # required — path to the .py file, relative to the yaml config
function: my_transform # required — module-level function name to call
step_type: polars # required — "polars", "pandas", or "datafusion" (default: datafusion)
context: # optional — any yaml value, passed as context to the function
threshold: 1000000
Pandas
Set step_type: pandas. The function must use the (data, context) signature described in Custom Steps with Pandas.
./steps/my_step.py:
import pandas as pd
def my_transform(data: dict[str, pd.DataFrame], context) -> dict[str, pd.DataFrame]:
threshold = context["threshold"] if context else 0
transfers = data["transfers"]
transfers = transfers[transfers["value"] > threshold].copy()
transfers["value_eth"] = transfers["value"] / 1e18
data["transfers"] = transfers
return data
- kind: python_file
config:
file: ./steps/my_step.py # required — path to the .py file, relative to the yaml config
function: my_transform # required — module-level function name to call
step_type: pandas # required — "polars", "pandas", or "datafusion" (default: datafusion)
context: # optional — any yaml value, passed as context to the function
threshold: 1000000
DataFusion
Set step_type: datafusion (or omit it, since datafusion is the default). The function must use the (session_ctx, data, context) signature described in Custom Steps with DataFusion.
./steps/my_step.py:
def my_sql_transform(session_ctx, data, context):
min_block = context["min_block"] if context else 0
data["transfers"] = session_ctx.sql(f"""
SELECT t.*, b.timestamp
FROM transfers t
JOIN blocks b ON b.number = t.block_number
WHERE t.block_number >= {min_block}
""")
return data
- kind: python_file
config:
file: ./steps/my_step.py # required — path to the .py file, relative to the yaml config
function: my_sql_transform # required — module-level function name to call
step_type: datafusion # optional — default when step_type is omitted
context: # optional — any yaml value, passed as context to the function
min_block: 18500000
SQL (yaml only)
The sql kind is a yaml-only convenience step that lets you write DataFusion SQL directly in your config file without needing a separate Python file. Under the hood it builds a DataFusion runner and executes each query sequentially against the current in-memory tables.
All in-memory tables are available by name in every query. Queries run in order, and the output of one query is available to the next. Each query’s result is stored back into the pipeline data:
CREATE TABLE name AS SELECT ...— stores the result undername, making it available for subsequent steps and for the writer.CREATE OR REPLACE TABLEandCREATE TABLE IF NOT EXISTSare also supported.CREATE VIEW name AS SELECT ...— same as above; the view is registered in the session and stored undername.- Plain
SELECT ...— stores the result under the keysql_result, overwriting the previous value if multiple plain selects are used.
Existing tables not referenced in any query are preserved unchanged.
yaml
- kind: sql
config:
queries: # required — one or more SQL strings, run in order
- >
CREATE TABLE transfers AS
SELECT *
FROM logs
WHERE topic0 = '0xddf252ad...'
- >
CREATE OR REPLACE TABLE enriched AS
SELECT t.*, b.timestamp
FROM transfers t
JOIN blocks b ON b.number = t.block_number
Writers
Writers define where the processed data is stored after each pipeline batch. Each writer adapts the Arrow RecordBatch output to a specific storage format.
Available Writers
| Writer | Format | Best for |
|---|---|---|
DUCKDB | DuckDB database | Local analytics, prototyping |
CLICKHOUSE | ClickHouse | Production analytics at scale |
ICEBERG | Apache Iceberg | Data lake with ACID transactions |
DELTA_LAKE | Delta Lake | Data lake with versioning |
PYARROW_DATASET | Parquet files | Simple file-based storage |
POSTGRESQL | PostgreSQL | Relational storage, existing PostgreSQL instances |
CSV | CSV files | Simple text export, interoperability |
Each table in the pipeline data is written as a separate table or directory named after its key (e.g. "transfers" → transfers table or transfers/ directory).
All writers support automatic table creation. tiders infers the output schema from the Arrow data and creates tables accordingly. No manual schema definition is needed.
A pipeline can write to more than one backend simultaneously by passing a list of writers. All writers receive the same processed data in parallel on each batch.
DuckDB
Inserts Arrow tables into a DuckDB database. Tables are auto-created on the first push using the Arrow schema. Decimal256 columns are automatically downcast to Decimal128(38, scale) since DuckDB does not support 256-bit decimals — use a cast_by_type step beforehand if you need control over overflow behavior.
Requires: pip install "tiders[duckdb]"
Python
import tiders as cc
# Option 1: plain path
writer = cc.Writer(
kind=cc.WriterKind.DUCKDB,
config=cc.DuckdbWriterConfig(
path="./data/output.duckdb", # path to create or connect to a DuckDB database
),
)
# Option 2: pre-built connection
import duckdb
duckdb_client=duckdb.connect("./data/output.duckdb")
writer = cc.Writer(
kind=cc.WriterKind.DUCKDB,
config=cc.DuckdbWriterConfig(
connection=duckdb_client, # optional — pre-built DuckDB connection
),
)
yaml
writer:
kind: duckdb
config:
path: data/output.duckdb # required
ClickHouse
Inserts Arrow tables into ClickHouse using the clickhouse-connect async client. Tables are auto-created on the first insert using the inferred Arrow schema. All tables except the anchor_table are inserted in parallel.
Requires: pip install "tiders[clickhouse]"
Python
import tiders as cc
from tiders.config import ClickHouseSkipIndex
# Option 1: plain connection parameters
writer = cc.Writer(
kind=cc.WriterKind.CLICKHOUSE,
config=cc.ClickHouseWriterConfig(
host="localhost", # optional, default: "localhost"
port=8123, # optional, default: 8123
username="default", # optional, default: "default"
password="", # optional, default: ""
database="default", # optional, default: "default"
secure=False, # optional, default: False
engine="MergeTree()", # optional, default: "MergeTree()"
order_by={"transfers": ["block_number", "log_index"]}, # optional, per-table ordering key columns.
codec={"transfers": {"data": "ZSTD(3)"}}, # optional, per-table, per-column compression codecs.
skip_index={"transfers": [ClickHouseSkipIndex(name="idx_value", val="value", type_="minmax", granularity=1)]}, # optional, per-table list of data-skipping indexes added after table creation.
create_tables=True, # optional, default: True.
anchor_table="transfers", # optional, default: None.
),
)
# Option 2: pre-built async client
import clickhouse_connect
clickhouse_client = await clickhouse_connect.get_async_client(
host="localhost", port=8123, username="default", password="", database="default",
)
writer = cc.Writer(
kind=cc.WriterKind.CLICKHOUSE,
config=cc.ClickHouseWriterConfig(
client=clickhouse_client, # optional — pre-built async ClickHouse client
),
)
yaml
writer:
kind: clickhouse
config: # include params to create the ClickHouseClient.
host: localhost # required
port: 8123 # optional, default: 8123
username: default # optional, default: default
password: ${CH_PASSWORD} # optional, default: ""
database: default # optional, default: default
secure: false # optional, default: false
engine: MergeTree() # optional, default: MergeTree()
order_by: # optional — per-table list of ORDER BY columns
transfers: [block_number, log_index]
codec: # optional — per-table, per-column compression codec
transfers:
data: ZSTD(3)
create_tables: true # optional, default: true
anchor_table: transfers # optional — written last after all other tables
skip_index (Python only): ClickHouseSkipIndex takes name, val (index expression), type_ (e.g. "minmax", "bloom_filter"), and granularity. Indexes are added after table creation via ALTER TABLE ... ADD INDEX.
Iceberg
Writes Arrow tables into an Apache Iceberg catalog. Each table is created in the specified namespace if it does not already exist.
Requires: pip install "tiders[iceberg]"
Python
import tiders as cc
# Option 1: plain catalog parameters
writer = cc.Writer(
kind=cc.WriterKind.ICEBERG,
config=cc.IcebergWriterConfig(
namespace="my_namespace", # required — Iceberg namespace (database) to write tables into
catalog_uri="sqlite:///catalog.db", # required — URI for the Iceberg catalog
warehouse="s3://my-bucket/iceberg/", # required — warehouse root URI for the catalog
catalog_type="sql", # optional, default: "sql"
write_location="s3://my-bucket/iceberg/", # optional — storage URI for data files, default: warehouse
),
)
# Option 2: pre-built pyiceberg catalog
from pyiceberg.catalog import load_catalog
catalog = load_catalog(
"my_catalog",
type="sql",
uri="sqlite:///catalog.db",
warehouse="s3://my-bucket/iceberg/",
)
writer = cc.Writer(
kind=cc.WriterKind.ICEBERG,
config=cc.IcebergWriterConfig(
namespace="my_namespace", # required
catalog=catalog, # optional — pre-built pyiceberg Catalog instance
write_location="s3://my-bucket/iceberg/", # optional — default: warehouse
),
)
yaml
writer:
kind: iceberg
config:
namespace: my_namespace # required
catalog_uri: sqlite:///catalog.db # required
warehouse: s3://my-bucket/iceberg/ # required
catalog_type: sql # optional, default: sql
write_location: s3://my-bucket/iceberg/ # optional, default: warehouse
Delta Lake
Appends Arrow tables to Delta tables using deltalake.write_deltalake with schema merging enabled. Each table is stored at <data_uri>/<table_name>/. All tables except the anchor_table are written in parallel.
Requires: pip install "tiders[delta_lake]"
Python
import tiders as cc
writer = cc.Writer(
kind=cc.WriterKind.DELTA_LAKE,
config=cc.DeltaLakeWriterConfig(
data_uri="s3://my-bucket/delta/", # required — base URI; each table is written to <data_uri>/<table_name>/
partition_by={"transfers": ["block_number"]}, # optional — per-table list of partition columns
storage_options={"AWS_REGION": "us-east-1"}, # optional — cloud storage credentials passed to deltalake
anchor_table="transfers", # optional — written last after all other tables
),
)
yaml
writer:
kind: delta_lake
config:
data_uri: s3://my-bucket/delta/ # required
partition_by: # optional — per-table list of partition columns
transfers: [block_number]
storage_options: # optional — cloud storage credentials
AWS_REGION: us-east-1
AWS_ACCESS_KEY_ID: ${AWS_KEY}
anchor_table: transfers # optional — written last after all other tables
PyArrow Dataset (Parquet)
Writes Arrow tables as Parquet files using pyarrow.dataset.write_dataset. Each table is stored under <base_dir>/<table_name>/. A monotonic counter is appended to the file name to avoid collisions across successive pushes. All tables except the anchor_table are written in parallel.
Python
import tiders as cc
writer = cc.Writer(
kind=cc.WriterKind.PYARROW_DATASET,
config=cc.PyArrowDatasetWriterConfig(
base_dir="./data/output", # required — root directory; each table is written to <base_dir>/<table_name>/
partitioning={"transfers": ["block_number"]}, # optional — per-table list of partition columns or pyarrow.dataset.Partitioning
partitioning_flavor={"transfers": "hive"}, # optional — per-table partitioning flavor
basename_template="part-{i}.parquet", # optional — output file name template, default: "part-{i}.parquet"
max_rows_per_file=1_000_000, # optional — max rows per output file, default: 0 (unlimited)
min_rows_per_group=0, # optional — min rows per Parquet row group, default: 0
max_rows_per_group=1024 * 1024, # optional — max rows per Parquet row group, default: 1048576
max_partitions=1024, # optional — max number of partitions, default: 1024
max_open_files=1024, # optional — max files open simultaneously, default: 1024
use_threads=True, # optional — use threads for writing, default: True
create_dir=True, # optional — create output directory if missing, default: True
anchor_table="transfers", # optional — written last after all other tables
),
)
yaml
writer:
kind: pyarrow_dataset
config:
base_dir: data/output # required
partitioning: # optional — per-table list of partition columns
transfers: [block_number]
partitioning_flavor: # optional — per-table flavor (e.g. "hive")
transfers: hive
basename_template: part-{i}.parquet # optional — output file name template
max_rows_per_file: 1000000 # optional, default: 0 (unlimited)
min_rows_per_group: 0 # optional, default: 0
max_rows_per_group: 1048576 # optional, default: 1048576
max_partitions: 1024 # optional, default: 1024
max_open_files: 1024 # optional, default: 1024
use_threads: true # optional, default: true
create_dir: true # optional, default: true
anchor_table: transfers # optional — written last after all other tables
CSV
Writes Arrow tables as CSV files using pyarrow.csv.write_csv. Each table is written to <base_dir>/<table_name>.csv. On successive pushes the file is appended to. All tables except the anchor_table are written in parallel.
Python
import tiders as cc
writer = cc.Writer(
kind=cc.WriterKind.CSV,
config=cc.CsvWriterConfig(
base_dir="./data/output", # required — root directory; each table is written to <base_dir>/<table_name>.csv
delimiter=",", # optional — field delimiter character, default: ","
include_header=True, # optional — write a header row, default: True
create_dir=True, # optional — create output directory if missing, default: True
anchor_table="transfers", # optional — written last after all other tables
),
)
yaml
writer:
kind: csv
config:
base_dir: data/output # required
delimiter: "," # optional, default: ","
include_header: true # optional, default: true
create_dir: true # optional, default: true
anchor_table: transfers # optional — written last after all other tables
PostgreSQL
Inserts Arrow tables into PostgreSQL using the COPY protocol via psycopg v3. Tables are auto-created on the first push using CREATE TABLE IF NOT EXISTS derived from the Arrow schema. All tables except the anchor_table are inserted in parallel.
Requires: pip install "tiders[postgresql]"
Unsupported raw blockchain fields
The PostgreSQL writer does not support List, Struct, or Map Arrow columns. Writing raw EVM or SVM data directly will fail unless you use a step to flatten or drop the affected columns first.
EVM fields that require preprocessing:
| Table | Field | Arrow type |
|---|---|---|
blocks | uncles | List(Binary) |
blocks | withdrawals | List(Struct(index, validator_index, address, amount)) |
transactions | access_list | List(Struct(address, storage_keys)) |
transactions | blob_versioned_hashes | List(Binary) |
traces | trace_address | List(UInt64) |
SVM fields that require preprocessing:
| Table | Field | Arrow type |
|---|---|---|
transactions | account_keys | List(Binary) |
transactions | signatures | List(Binary) |
transactions | loaded_readonly_addresses | List(Binary) |
transactions | loaded_writable_addresses | List(Binary) |
transactions | address_table_lookups | List(Struct(account_key, writable_indexes, readonly_indexes)) |
logs | instruction_address | List(UInt32) |
instructions | instruction_address | List(UInt32) |
instructions | rest_of_accounts | List(Binary) |
Python
import tiders as cc
# Option 1: plain connection parameters (recommended)
writer = cc.Writer(
kind=cc.WriterKind.POSTGRESQL,
config=cc.PostgresqlWriterConfig(
host="localhost", # optional, default: "localhost"
port=5432, # optional, default: 5432
user="postgres", # optional, default: "postgres"
password="secret", # optional, default: "postgres"
dbname="mydb", # optional, default: "postgres"
schema="public", # optional — PostgreSQL schema (namespace), default: "public"
create_tables=True, # optional — auto-create tables on first push, default: True
anchor_table="transfers", # optional — written last after all other tables, default: None
),
)
# Option 2: pre-built async connection
import psycopg
import asyncio
connection = asyncio.get_event_loop().run_until_complete(
psycopg.AsyncConnection.connect(
"host=localhost port=5432 dbname=mydb user=postgres password=secret",
autocommit=False,
)
)
writer = cc.Writer(
kind=cc.WriterKind.POSTGRESQL,
config=cc.PostgresqlWriterConfig(
connection=connection, # optional — pre-built psycopg.AsyncConnection
schema="public", # optional, default: "public"
create_tables=True, # optional, default: True
anchor_table="transfers", # optional, default: None
),
)
yaml
writer:
kind: postgresql
config:
host: localhost # required
dbname: postgres # optional, default: postgres
port: 5432 # optional, default: 5432
user: postgres # optional, default: postgres
password: ${PG_PASSWORD} # optional, default: postgres
schema: public # optional, default: public
create_tables: true # optional, default: true
anchor_table: transfers # optional — written last after all other tables
Examples
Complete working examples that demonstrate different tiders features. Each example is designed to highlight a different aspect of the framework — start with the one closest to your use case.
| Example | Chain | Provider | Decoding | Writer |
|---|---|---|---|---|
| rETH Transfer (no code) | Ethereum (EVM) | Hypersync (Envio) | EVM event decode | Parquet (Pyarrow Dataset) |
| Jupiter Swaps | Solana (SVM) | SQD | SVM instruction decode | DuckDB |
| Uniswap V3 | Ethereum (EVM) | HyperSync / SQD / RPC | EVM event decode (factory + children) | DuckDB / Parquet / Delta Lake / ClickHouse / Iceberg |
What each example teaches
-
rETH Transfer — The simplest starting point. Uses a YAML config with no Python code, showing how to index a single event from a single contract. Also demonstrates the SQL step for joining decoded data with block timestamps.
-
Jupiter Swaps — Use Tiders’ Python SDK and switches to Solana (SVM). Shows how to decode instruction data, use a custom Polars step for joining tables, and run post-pipeline SQL in DuckDB to enrich data with external metadata.
-
Uniswap V3 — Demonstrates the factory + children two-stage indexing pattern, the most common multi-pipeline pattern in DeFi. Shows how to chain two pipelines where the first discovers contracts and the second indexes their events, how to dynamically generate decode steps from an ABI, and how to use table aliases to give descriptive names to raw ingested tables.
All examples are available in the examples/ directory of the tiders repository.
rETH Transfers (No-Code)
This example indexes Transfer events from the Rocket Pool rETH token contract using a YAML config — no Python required.
Source: examples/reth_transfer_nocode/
Run
cd examples/reth_transfer_nocode
cp .env.example .env
# Fill PROVIDER_URL and HYPERSYNC_BEARER_TOKEN in .env
tiders start
What it does
- Queries logs matching the
Transferevent from the rETH contract via HyperSync - Decodes the raw log data into typed
from,to, andamountcolumns - Casts
decimal256todecimal128, unnecessary for PyArrow dataset (Parquet), but include if writer doesn’t support decimal256 values - Hex-encodes binary fields for readability
- Joins decoded transfer data with block timestamps via SQL step, so the transfer table include a timestamp
- Writes to a PyArrow dataset
Full config
project:
name: rETH_transfer
description: Index rETH Transfer events from the Rocket Pool rETH token contract.
repository: https://github.com/yulesa/tiders/example/reth_transfer_nocode
provider:
kind: hypersync
url: ${PROVIDER_URL}
bearer_token: ${HYPERSYNC_BEARER_TOKEN}
contracts:
- name: RocketTokenRETH
address: 0xae78736Cd615f374D3085123A210448E74Fc6393
abi: ./RocketTokenRETH.abi.json
query:
kind: evm
from_block: 13325304
to_block: 13325404
logs:
- address: RocketTokenRETH.address
topic0: "Transfer(address,address,uint256)"
include_blocks: true
fields:
log: [address, topic0, topic1, topic2, topic3, data, block_number, transaction_hash, log_index]
block: [number, timestamp]
steps:
- kind: evm_decode_events
config:
event_signature: "Transfer(address indexed from, address indexed to, uint256 amount)"
output_table: transfers
allow_decode_fail: true
- kind: cast_by_type
name: i256_to_i128
config:
from_type: "decimal256(76,0)"
to_type: "decimal128(38,0)"
allow_cast_fail: true
- kind: hex_encode
- kind: sql
config:
queries:
- >
CREATE OR REPLACE TABLE transfers AS
SELECT transfers.*, blocks.timestamp AS block_timestamp
FROM transfers
INNER JOIN blocks ON blocks.number = transfers.block_number
writer:
kind: pyarrow_dataset
config:
base_dir: data/pyarrow
Key concepts
Contract references — the contracts: section loads RocketTokenRETH.abi.json and makes the contract available by name. topic0: "Transfer(address,address,uint256)" is a human-readable event signature; the CLI converts it to a Keccak-256 hash automatically.
Decode step — evm_decode_events reads the raw topic1, topic2, and data columns and produces typed from, to, and amount columns in a new transfers table.
Cast step — EVM uint256 values are decoded as decimal256(76,0). The cast_by_type step downcasts them to decimal128(38,0). This is step is dispensable in PyArrow datasets (Parquet), but necessary in databases that don’t support decimal256(76,0).
SQL step — the sql step runs DataFusion SQL against the in-memory tables. Both transfers and blocks are available because include_blocks: true was set on the log request.
Environment variables — credentials stay in .env and are referenced as ${PROVIDER_URL} in the YAML. The CLI loads .env automatically from the config directory.
Jupiter Swaps (SVM)
This example builds a Solana indexer that fetches Jupiter DEX swap instructions, decodes them into typed fields, joins with block and transaction data using Polars, and writes enriched swap analytics to DuckDB.
Source: examples/jup_swap/jup_swap.py
Run
uv run jup_swap.py --from_block 330447751 --to_block 330448751
Pipeline Overview
- Queries Solana instructions filtered by Jupiter program ID (
JUP6LkbZbjS1jKKwapdHNy74zcZ3tLUZoi5QNyVTaV4) and swap event discriminator (0xe445a52e51cb9a1d40c6cde8260871e2), along with related blocks and transactions - Decodes instruction data into typed swap fields (AMM, input/output mints, amounts) using
InstructionSignature - Joins block and transaction data into the decoded instructions table via a custom Polars step
- Base58-encodes binary fields (public keys, hashes) into human-readable strings
- Writes to DuckDB
- Enriches with token metadata and AMM names via DuckDB post-processing SQL
Provider
Connects to the SQD portal network for Solana mainnet data:
provider = ProviderConfig(
kind=ProviderKind.SQD,
url="https://portal.sqd.dev/datasets/solana-mainnet",
)
Query
The query fetches instructions, blocks, and transactions for a given block range. Field selection controls which columns are returned per table, minimizing bandwidth. The InstructionRequest filters rows to only Jupiter swap events by program_id=["JUP…4"] and discriminator=["0xe4…e2"]. Setting include_transactions=True pulls in the transaction table for matching instructions, and include_all_blocks=True returns all blocks in the range regardless of matches.
query = IngestQuery(
kind=QueryKind.SVM,
params=Query(
from_block=from_block,
to_block=actual_to_block,
include_all_blocks=True,
fields=Fields(
instruction=InstructionFields(
block_slot=True,
block_hash=True,
transaction_index=True,
instruction_address=True,
program_id=True,
a0=True, a1=True, a2=True, a3=True, a4=True,
a5=True, a6=True, a7=True, a8=True, a9=True,
data=True,
error=True,
),
block=BlockFields(
slot=True,
hash=True,
timestamp=True,
),
transaction=TransactionFields(
block_slot=True,
block_hash=True,
transaction_index=True,
signature=True,
),
),
instructions=[
InstructionRequest(
program_id=["JUP6LkbZbjS1jKKwapdHNy74zcZ3tLUZoi5QNyVTaV4"],
discriminator=["0xe445a52e51cb9a1d40c6cde8260871e2"],
include_transactions=True,
)
],
),
)
Instruction Signature
Defines the layout of the Jupiter Aggregator v6 SwapEvent instruction data. The discriminator identifies the instruction type, and params describes the binary layout: three 32-byte public keys (AMM, InputMint, OutputMint) and two u64 amounts. Signatures can be sourced from IDLs, SolScan, or contract source code.
For more information read the instructions signatures documentation.
from tiders_core.svm_decode import InstructionSignature, ParamInput, DynType, FixedArray
instruction_signature = InstructionSignature(
discriminator="0xe445a52e51cb9a1d40c6cde8260871e2",
params=[
ParamInput(name="Amm", param_type=FixedArray(DynType.U8, 32)),
ParamInput(name="InputMint", param_type=FixedArray(DynType.U8, 32)),
ParamInput(name="InputAmount", param_type=DynType.U64),
ParamInput(name="OutputMint", param_type=FixedArray(DynType.U8, 32)),
ParamInput(name="OutputAmount", param_type=DynType.U64),
],
accounts_names=[],
)
Transformation Steps
Steps are executed sequentially. Each step receives the transformed output of the previous one.
SVM_DECODE_INSTRUCTIONS— Decodes raw instructiondatausing the signature above.hstack=Trueappends decoded columns alongside the original fields.allow_decode_fail=Truekeeps rows that fail to decode. The output is written to a new tablejup_swaps_decoded_instructions.POLARS(custom step) — Runs a user-defined function that joins block timestamps and transaction signatures into the decoded instructions table using Polars DataFrames.BASE58_ENCODE— Converts all binary columns (public keys, hashes) to base58 strings.
obs: Tiders has available JOIN_BLOCK_DATA and JOIN_SVM_TRANSACTION_DATA steps to make joins effortlessly. We are using custom polars funtions to set an example.
steps = [
cc.Step(
kind=cc.StepKind.SVM_DECODE_INSTRUCTIONS,
config=cc.SvmDecodeInstructionsConfig(
instruction_signature=instruction_signature,
hstack=True,
allow_decode_fail=True,
output_table="jup_swaps_decoded_instructions",
),
),
cc.Step(
kind=cc.StepKind.POLARS,
config=cc.PolarsStepConfig(runner=process_data),
),
cc.Step(
kind=cc.StepKind.BASE58_ENCODE,
config=cc.Base58EncodeConfig(),
),
]
Custom Polars Step
The process_data function joins block and transaction tables into the decoded instructions table. The blocks join brings in timestamp; the transactions join brings in signature.
def process_data(
data: dict[str, pl.DataFrame], ctx: Optional[Any]
) -> dict[str, pl.DataFrame]:
table = data["jup_swaps_decoded_instructions"]
table = table.join(data["blocks"], left_on="block_slot", right_on="slot")
table = table.join(data["transactions"], on=["block_slot", "transaction_index"])
return {"jup_swaps_decoded_instructions": table}
Writer
Writes the pipeline output to a local DuckDB database:
connection = duckdb.connect("data/solana_swaps.db")
writer = cc.Writer(
kind=cc.WriterKind.DUCKDB,
config=cc.DuckdbWriterConfig(
connection=connection.cursor(),
),
)
Running the Pipeline
pipeline = cc.Pipeline(
provider=provider,
query=query,
writer=writer,
steps=steps,
)
await run_pipeline(pipeline_name="jup_swaps", pipeline=pipeline)
Post-Pipeline Analytics
After the pipeline writes jup_swaps_decoded_instructions to DuckDB, a SQL post-processing step enriches the data with token metadata and AMM names from CSV lookup tables, producing a jup_swaps table similar to a dex.trades analytics table:
CREATE OR REPLACE TABLE solana_amm AS
SELECT * FROM read_csv('./solana_amm.csv');
CREATE OR REPLACE TABLE solana_tokens AS
SELECT * FROM read_csv('./solana_tokens.csv');
CREATE OR REPLACE TABLE jup_swaps AS
SELECT
di.amm AS amm,
sa.amm_name AS amm_name,
case when di.inputmint > di.outputmint
then it.token_symbol || '-' || ot.token_symbol
else ot.token_symbol || '-' || it.token_symbol
end as token_pair,
it.token_symbol as input_token,
di.inputmint AS input_token_address,
di.inputamount AS input_amount_raw,
it.token_decimals AS input_token_decimals,
di.inputamount / 10^it.token_decimals AS input_amount,
ot.token_symbol as output_token,
di.outputmint AS output_token_address,
di.outputamount AS output_amount_raw,
ot.token_decimals AS output_token_decimals,
di.outputamount / 10^ot.token_decimals AS output_amount,
di.block_slot AS block_slot,
di.transaction_index AS transaction_index,
di.instruction_address AS instruction_address,
di.timestamp AS block_timestamp
FROM jup_swaps_decoded_instructions di
LEFT JOIN solana_amm sa ON di.amm = sa.amm_address
LEFT JOIN solana_tokens it ON di.inputmint = it.token_address
LEFT JOIN solana_tokens ot ON di.outputmint = ot.token_address;
Output
SELECT * FROM jup_swaps_decoded_instructions LIMIT 3;
SELECT * FROM jup_swaps LIMIT 3;
Uniswap V3 (Factory + Children Pattern)
This example demonstrates the factory + children indexing pattern — one of the most common patterns in crypto data engineering. A Factory contract deploys child contracts (pools) on-chain. To index them you first index the factory to discover the children and then index their events. This pattern applies to Uniswap (V2/V3), Aave, Compound, Curve, and many other DeFi protocols.
Source: examples/uniswap_v3/
Run
cd examples/uniswap_v3
cp .env.example .env
uv run uniswap_v3.py --provider <hypersync|sqd|rpc> --from_block 12369621 --to_block 12370621
# [--rpc_url URL] \ # only needed with --provider rpc
# [--database BACKEND] # default: pyarrow. Options: pyarrow, duckdb, delta_lake, clickhouse, iceberg
Pipeline Overview
This example runs two pipelines sequentially:
Stage 1 — Discover pools from the Factory:
- Queries
PoolCreatedlogs from the Uniswap V3 Factory contract - Decodes raw log data into typed columns (
token0,token1,fee,tickSpacing,pool)
Stage 2 — Index events from discovered pools:
- Reads pool addresses from the Stage 1 output (plain Python, not a Tiders feature)
- Queries ALL logs emitted by those pool addresses (no topic filter — fetches every event type)
- Decodes each known pool event (Swap, Mint, Burn, Flash, etc.) into its own output table
- Writes all decoded event tables to the chosen backend
ABI Setup
evm_abi_events() parses an ABI JSON file and returns event descriptors. We build a dict keyed by event name for easy access to events params.
The same pattern is used for pool events. Both ABI JSON files are included in the example directory.
factory_events = {
ev.name: {
"topic0": ev.topic0,
"signature": ev.signature,
"name_snake_case": ev.name_snake_case,
"selector_signature": ev.selector_signature,
}
for ev in evm_abi_events(_FACTORY_ABI_JSON)
}
Stage 1 — Pool Discovery Pipeline
Query
Fetches logs from the Factory contract address, filtered by the PoolCreated topic0 hash. The fields parameter selects which log columns to include.
query = ingest.Query(
kind=ingest.QueryKind.EVM,
params=ingest.evm.Query(
from_block=from_block,
to_block=to_block,
logs=[
ingest.evm.LogRequest(
address=[UNISWAP_V3_FACTORY],
topic0=[factory_events["PoolCreated"]["topic0"]],
)
],
fields=ingest.evm.Fields(
log=ingest.evm.LogFields(
block_number=True, block_hash=True,
transaction_hash=True, log_index=True,
address=True, topic0=True, topic1=True,
topic2=True, topic3=True, data=True,
),
),
),
)
Steps
EVM_DECODE_EVENTS— Decodes the rawPoolCreatedlog into typed columns:token0,token1,fee,tickSpacing, andpool. The decoded output goes into a newuniswap_v3_pool_createdtable.HEX_ENCODE— Converts all binary columns to0x…hex strings.
steps = [
cc.Step(
kind=cc.StepKind.EVM_DECODE_EVENTS,
config=cc.EvmDecodeEventsConfig(
event_signature=factory_events["PoolCreated"]["signature"],
input_table=POOL_CREATED_LOGS_TABLE,
output_table=POOL_CREATED_TABLE,
allow_decode_fail=False,
),
),
cc.Step(
kind=cc.StepKind.HEX_ENCODE,
config=cc.HexEncodeConfig(),
),
]
Tiders ingests raw EVM logs into a default logs table. table_aliases renames it so the decode step can reference it by a descriptive name
Bridging Stages
After Stage 1 writes the decoded pool data, we read back the pool addresses using plain Python. Tiders doesn’t prescribe how you connect pipeline stages — use whatever method fits your storage backend:
pool_addresses = await load_pool_addresses(database)
Stage 2 — Pool Events Pipeline
Query
Re-queries the same block range, but now filtered to the discovered pool addresses. No topic filter — we want ALL events from these pools:
query = ingest.Query(
kind=ingest.QueryKind.EVM,
params=ingest.evm.Query(
from_block=from_block,
to_block=to_block,
logs=[
ingest.evm.LogRequest(
address=pool_addresses,
)
],
...
),
)
Steps
A decode step is created dynamically for each event in the pool contracts. Each event gets decoded from the shared raw logs table into its own output table (e.g., uniswap_v3_pool_swap, uniswap_v3_pool_mint).
for _, event in pool_events.items():
output_table = f"uniswap_v3_pool_{event['name_snake_case']}"
steps.append(
cc.Step(
kind=cc.StepKind.EVM_DECODE_EVENTS,
config=cc.EvmDecodeEventsConfig(
event_signature=event["signature"],
input_table=POOL_EVENTS_TABLE,
output_table=output_table,
allow_decode_fail=True,
filter_by_topic0=True,
),
),
)
filter_by_topic0=True— only attempts to decode logs whose topic0 matches this event’s signature, since the raw table contains mixed event types.allow_decode_fail=True— skips logs that don’t match the expected format without raising errors.
After decoding, a CAST_BY_TYPE step downcasts decimal256 to decimal128, and HEX_ENCODE converts binary fields to hex strings.
Key Concepts
Factory + children pattern — The most common multi-stage indexing pattern in DeFi. Stage 1 reads the factory to discover child contracts; Stage 2 indexes the children. This same approach works for any protocol with factory-deployed contracts (Uniswap V2 pairs, Aave markets, Compound cTokens, etc.).
Table aliases — Tiders names raw ingested tables generically (logs, blocks, etc.). Use table_aliases to give them descriptive names per pipeline, which is especially important when running multiple pipelines that write to the same database.
Dynamic decode steps — Instead of hardcoding a decode step for each event, this example loops over all events in the pool ABI and creates a step for each. This keeps the pipeline maintainable as ABIs evolve.
Cast step — EVM int256/uint256 values are decoded as decimal256(76,0). The cast_by_type step downcasts to decimal128(38,0) for databases that don’t support 256-bit decimals. This step is dispensable in PyArrow datasets (Parquet).
Core Libraries Overview
tiders-core is a Rust workspace that provides the high-performance engine behind tiders. It handles data ingestion, ABI decoding, type casting, encoding, and schema definitions.
The Python SDK calls into these libraries via PyO3 bindings.
Crates
| Crate | Purpose |
|---|---|
tiders-ingest | Data provider orchestration and streaming |
tiders-evm-decode | EVM event and function ABI decoding |
tiders-svm-decode | Solana instruction and log decoding |
tiders-cast | Arrow column type casting (blockchain-aware) |
tiders-evm-schema | Arrow schema definitions for EVM data |
tiders-svm-schema | Arrow schema definitions for SVM data |
tiders-query | Query execution and filtering |
tiders-core | Re-export crate aggregating all of the above |
tiders-core-python | PyO3 Python bindings |
Dependency Graph
tiders-core (re-exports)
├── tiders-ingest
│ ├── tiders-evm-schema
│ ├── tiders-svm-schema
│ └── tiders-rpc-client (optional, for RPC provider)
├── tiders-evm-decode
├── tiders-svm-decode
├── tiders-cast
└── tiders-query
Rust API Reference
Auto-generated API documentation for all crates:
Python API
The tiders_core Python module exposes these functions directly:
| Function | Description |
|---|---|
cast(), cast_schema() | Cast columns using a name-to-type mapping |
cast_by_type(), cast_schema_by_type() | Cast all columns of one type to another |
hex_encode(), prefix_hex_encode() | Hex-encode binary data |
base58_encode(), base58_encode_bytes() | Base58-encode binary data |
evm_decode_events() | Decode EVM log events |
evm_decode_call_inputs(), evm_decode_call_outputs() | Decode EVM function calls |
evm_signature_to_topic0() | Compute topic0 hash from event signature |
svm_decode_instructions(), svm_decode_logs() | Decode Solana data |
ingest.start_stream() | Start a streaming data ingestion pipeline |
Ingest
The tiders-ingest crate handles data fetching from blockchain data providers. It provides a unified streaming interface regardless of the backend (HyperSync, SQD, or RPC).
Python Usage
from tiders_core.ingest import (
ProviderConfig,
ProviderKind,
Query,
QueryKind,
start_stream,
)
Provider Configuration
provider = ProviderConfig(
kind=ProviderKind.HYPERSYNC, # or SQD, RPC
url="https://eth.hypersync.xyz",
stop_on_head=False, # keep polling for new blocks
batch_size=100, # blocks per batch
)
EVM Query
from tiders_core.ingest import evm
query = Query(
kind=QueryKind.EVM,
params=evm.Query(
from_block=18_000_000,
to_block=18_001_000,
logs=[evm.LogRequest(...)],
transactions=[evm.TransactionRequest(...)],
fields=evm.Fields(...),
),
)
SVM Query
from tiders_core.ingest import svm
query = Query(
kind=QueryKind.SVM,
params=svm.Query(
from_block=330_000_000,
instructions=[svm.InstructionRequest(...)],
fields=svm.Fields(...),
),
)
Rust API
See the tiders_ingest rustdoc for the full Rust API.
The main entry point is start_stream(), which returns an async stream of Result<RecordBatch> items.
EVM Decode
The tiders-evm-decode crate decodes EVM smart contract data (events and function calls) from raw bytes into typed Arrow columns.
Python Usage
Decode Events
from tiders_core import evm_decode_events, evm_signature_to_topic0
# Compute topic0 for filtering
topic0 = evm_signature_to_topic0("Transfer(address,address,uint256)")
# Decode log records into typed columns
decoded = evm_decode_events(
record_batch,
"Transfer(address indexed from, address indexed to, uint256 amount)",
)
Decode Function Calls
from tiders_core import evm_decode_call_inputs, evm_decode_call_outputs
inputs = evm_decode_call_inputs(record_batch, "transfer(address to, uint256 amount)")
outputs = evm_decode_call_outputs(record_batch, "balanceOf(address) returns (uint256)")
Get Arrow Schema
from tiders_core import evm_event_signature_to_arrow_schema
schema = evm_event_signature_to_arrow_schema(
"Transfer(address indexed from, address indexed to, uint256 amount)"
)
How It Works
- Parses the Solidity ABI signature string
- Uses alloy
DynSolEvent/DynSolCallfor ABI decoding - Maps Solidity types to Arrow types (addresses, uint256, bytes, nested structs, arrays)
- Returns an Arrow RecordBatch with decoded columns
Rust API
See the tiders_evm_decode rustdoc for the full API.
SVM Decode
The tiders-svm-decode crate decodes Solana program instructions and logs from raw bytes into typed Arrow columns.
Python Usage
Decode Instructions
from tiders_core.svm_decode import InstructionSignature, ParamInput, DynType, FixedArray
# Define the instruction layout
signature = InstructionSignature(
discriminator="0xe445a52e51cb9a1d40c6cde8260871e2",
params=[
ParamInput(name="Amm", param_type=FixedArray(DynType.U8, 32)),
ParamInput(name="InputMint", param_type=FixedArray(DynType.U8, 32)),
ParamInput(name="InputAmount", param_type=DynType.U64),
ParamInput(name="OutputMint", param_type=FixedArray(DynType.U8, 32)),
ParamInput(name="OutputAmount", param_type=DynType.U64),
],
accounts_names=[],
)
from tiders_core import svm_decode_instructions
decoded = svm_decode_instructions(record_batch, signature)
Available Types
DynType.U8,U16,U32,U64,U128DynType.I8,I16,I32,I64,I128DynType.BOOL,DynType.STRINGFixedArray(inner_type, length)— fixed-size arraysDynArray(inner_type)— variable-length arrays
Get Arrow Schema
from tiders_core import instruction_signature_to_arrow_schema
schema = instruction_signature_to_arrow_schema(signature)
Rust API
See the tiders_svm_decode rustdoc for the full API.
Cast
The tiders-cast crate provides blockchain-aware type casting for Arrow columns. It extends standard Arrow casting with support for types common in blockchain data.
Python Usage
Cast by Column Name
import pyarrow as pa
from tiders_core import cast
# Cast specific columns to target types
casted_batch = cast(
[("block_number", pa.int64()), ("value", pa.decimal128(38, 0))],
record_batch,
)
Cast by Type
Convert all columns of one Arrow type to another:
from tiders_core import cast_by_type
# Convert all decimal256 columns to decimal128
casted_batch = cast_by_type(
pa.decimal256(76, 0),
pa.decimal128(38, 0),
record_batch,
allow_cast_fail=True,
)
This is useful when a downstream system (like DuckDB) doesn’t support certain types.
Encoding Utilities
The cast module also provides encoding/decoding functions:
from tiders_core import hex_encode, prefix_hex_encode, base58_encode
# Encode binary columns
hex_batch = hex_encode(record_batch) # "0a1b2c..."
prefixed = prefix_hex_encode(record_batch) # "0x0a1b2c..."
b58_batch = base58_encode(record_batch) # Base58 format
Rust API
See the tiders_cast rustdoc for the full API.
Schemas
The tiders-evm-schema and tiders-svm-schema crates define the canonical Arrow schemas for blockchain data tables.
EVM Schemas
Tables produced by EVM data sources:
| Table | Key Columns |
|---|---|
blocks | number, hash, parent_hash, timestamp, miner, gas_limit, gas_used, base_fee_per_gas, size, withdrawals |
transactions | hash, from, to, value, gas_used, effective_gas_price, cumulative_gas_used, contract_address |
logs | block_number, transaction_hash, log_index, address, topic0..topic3, data |
traces | block_number, transaction_hash, trace_address, type, from, to, value, input, output |
All binary fields (hashes, addresses) are stored as Arrow Binary type by default. Use the HEX_ENCODE step to convert them to readable strings.
SVM Schemas
Tables produced by SVM (Solana) data sources:
| Table | Key Columns |
|---|---|
blocks | slot, hash, timestamp, parent_slot |
transactions | block_slot, transaction_index, signature |
instructions | block_slot, transaction_index, instruction_address, program_id, data, a0..a9 |
Field Selection
You don’t fetch all columns by default. Use the Fields types in your query to select only the columns you need:
fields = ingest.evm.Fields(
block=ingest.evm.BlockFields(number=True, timestamp=True),
log=ingest.evm.LogFields(block_number=True, address=True, data=True),
)
This reduces network transfer, memory usage, and processing time.
Rust API
RPC Client Overview
tiders-rpc-client is a Rust library for fetching EVM blockchain data from any standard JSON-RPC endpoint and converting it to Apache Arrow format.
Unlike specialized providers (HyperSync, SQD), the RPC client works with any Ethereum-compatible JSON-RPC endpoint — Alchemy, Infura, QuickNode, local nodes, or any other provider.
Data Types and Pipelines
The client fetches blockchain data through three independent pipelines, each wrapping a specific RPC method:
| Pipeline | RPC Method | Data Types |
|---|---|---|
| Block | eth_getBlockByNumber | Blocks and transactions |
| Log | eth_getLogs | Event logs |
| Trace | trace_block or debug_traceBlockByNumber | Internal call traces |
The block pipeline also handles an internal transaction receipts pipeline via eth_getBlockReceipts. When the query requests receipt fields (e.g. status, gas_used, effective_gas_price), the block pipeline automatically fetches receipts and merges them into the transaction data.
When a query requires data from more than one pipeline, the client uses a multi-pipeline stream that runs all needed pipelines over the same block range in each batch and merges the results into a single response.
See Pipelines for details on each pipeline, the multi-pipeline stream, and the historical/live phases.
Key Features
- Streaming — data is returned as a stream of Arrow RecordBatches
- Adaptive concurrency — automatically adjusts parallelism based on provider response times
- Retry logic — built-in error recovery with exponential backoff
- Block range fallback — splits large
eth_getLogsranges when providers reject them - Field selection — fetch only the columns you need
Usage via tiders (Python)
The simplest way to use the RPC client is through the tiders Python SDK:
from tiders_core.ingest import ProviderConfig, ProviderKind
provider = ProviderConfig(
kind=ProviderKind.RPC,
url="https://eth-mainnet.g.alchemy.com/v2/YOUR_KEY",
stop_on_head=True,
batch_size=10,
)
See the RPC pipeline example for a complete working example.
Usage as a Rust Library
#![allow(unused)]
fn main() {
use tiders_rpc_client::{Client, ClientConfig, Query};
let config = ClientConfig::new("https://eth-mainnet.g.alchemy.com/v2/YOUR_KEY");
let client = Client::new(config);
let mut stream = client.stream(query);
while let Some(response) = stream.next().await {
let response = response?;
// response.blocks, response.transactions, response.logs, response.traces
}
}Rust API Reference
See the tiders_rpc_client rustdoc for the full API.
Pipelines
The RPC client organizes data fetching into three independent pipelines, each targeting a specific JSON-RPC method. When a query needs more than one pipeline, they are coordinated through a multi-pipeline stream.
Historical and Live Phases
Each pipeline operates in two phases:
- Historical — fetches all data from
from_blockto the chain head (orto_blockif specified), using concurrent tasks for throughput - Live — after catching up, polls for new blocks at the interval set by
head_poll_interval_millisand fetches data sequentially
If stop_on_head is set to true, the stream ends after the historical phase without entering live mode.
Block Pipeline
Fetches blocks and transactions using eth_getBlockByNumber.
- Sends batch RPC calls for a range of block numbers
- Transactions are extracted from the block response — no separate RPC call is needed
- Concurrency is managed by the block adaptive concurrency controller
eth_getBlockByNumber returns all transactions in a block with no server-side filtering. Setting filter fields (e.g. from_, to, sighash, status) on a TransactionRequest will produce an error. This functionality is only supported on other Tiders’ clients (sqd, hypersync). Ingest all transactions and filter post-indexing in your Tiders (python) pipeline or database instead.
Transaction Receipts
When the query requests transaction receipts fields (e.g. status, gas_used, effective_gas_price), the block pipeline automatically fetches transaction receipts via eth_getBlockReceipts and merges them into the transaction data. This runs as a sub-step inside the block pipeline, not as a separate pipeline.
Each block’s receipts are fetched individually in parallel, bounded by the single-block adaptive concurrency controller.
Log Pipeline
Fetches event logs using eth_getLogs.
- Constructs filters from the query’s log requests (addresses and topics)
- Concurrency is managed by the log adaptive concurrency controller
- Automatically splits large address lists into groups of 1000 per request
- When a provider rejects a block range as too large, the pipeline automatically limits the block range and retries
Log filters (addresses and topics) cannot be combined with include_* flags on the same LogRequest. When include_* flags activate additional pipelines, those pipelines return unfiltered data for the full block range — combining that with filtered logs would produce an inconsistent response. To use cross-pipeline coordination, remove the log filters and filter post-indexing.
Trace Pipeline
Fetches internal call traces using trace_block or debug_traceBlockByNumber.
- The trace method is auto-detected from the provider or can be overridden via
trace_methodin the configuration - Each block is traced individually in parallel, bounded by the single-block adaptive concurrency controller
- Each block is retried independently up to
max_num_retriestimes
trace_block and debug_traceBlockByNumber return all traces in a block with no server-side filtering. Setting filter fields (e.g. from_, to, call_type, sighash) on a TraceRequest will produce an error. This functionality is only supported on other Tiders’ clients (sqd, hypersync). Ingest all transactions and filter post-indexing in your Tiders (python) pipeline or database instead.
Note: Tracing requires a provider that supports block-level trace methods.
Multi-Pipeline Stream
When a query requires data from more than one pipeline, the client automatically switches to a coordinated multi-pipeline stream instead of running individual pipeline streams.
The coordinator:
- Divides the block range into fixed-size batches (sized by
batch_size). Unlike single-pipeline mode, the batch size does not adapt — it stays fixed throughout the run, so each response covers the same number of blocks. - Runs all needed pipelines for each batch over the same block range. Pipelines run sequentially within a batch to avoid interference between their adaptive concurrency controllers. Concurrency parameters carry over from one batch to the next.
- Merges the results into a single response containing blocks, transactions, logs, and traces for the entire batch.
This ensures that all data types in a response correspond to the same set of blocks.
Pipeline Selection
Which pipelines run is determined by the query:
- Block pipeline runs if the query requests block or transaction fields, or uses
include_all_blocks - Log pipeline runs if the query has log requests or selects log fields
- Trace pipeline runs if the query has trace requests or selects trace fields
Cross-pipeline include_* flags (e.g. include_transactions on a log request) can also activate additional pipelines.
If a query selects fields from multiple pipelines (e.g. both log and block fields) without setting include_* flags on any request, the client will return an error. This prevents accidental multi-pipeline queries. Either use include_* flags to opt in to cross-pipeline coordination, or split into separate queries.
RPC Client Configuration
The ClientConfig struct controls how the RPC client connects to the provider and manages request behavior. In Python, configuration is done through ProviderConfig with ProviderKind.RPC.
Basic Configuration
Rust
#![allow(unused)]
fn main() {
use tiders_rpc_client::ClientConfig;
let config = ClientConfig::new("https://eth-mainnet.g.alchemy.com/v2/YOUR_KEY");
}Python
from tiders_core.ingest import ProviderConfig, ProviderKind
provider = ProviderConfig(
kind=ProviderKind.RPC,
url="https://eth-mainnet.g.alchemy.com/v2/YOUR_KEY",
)
Configuration Options
| Option | Type | Default | Description |
|---|---|---|---|
url | String | (required) | The JSON-RPC endpoint URL |
bearer_token | Option<String> | None | Optional bearer token for authentication |
max_num_retries | u32 | 5000 | Maximum number of retries for a single RPC call |
retry_backoff_ms | u64 | 1000 | Fixed per-retry delay in milliseconds (used by alloy’s RetryBackoffLayer) |
retry_base_ms | u64 | 300 | Base delay for exponential backoff (used by per-block retry loops) |
retry_ceiling_ms | u64 | 10000 | Maximum delay for exponential backoff (used by per-block retry loops) |
req_timeout_millis | u64 | 30000 | Per-request HTTP timeout in milliseconds |
compute_units_per_second | Option<u64> | None | Compute-unit rate limit for alloy’s RetryBackoffLayer |
batch_size | Option<usize> | None | Initial number of blocks per batch in simple pipeline mode; Response size (in blocks) in multi-pipeline mode (impact memory usage). |
trace_method | Option<TraceMethod> | None | Override the trace method (trace_block or debug_trace_block_by_number) |
stop_on_head | bool | false | Stop the stream after reaching the chain head instead of entering live-polling mode |
head_poll_interval_millis | u64 | 1000 | How often to poll for new blocks during live mode, in milliseconds |
buffer_size | usize | 10 | Bounded channel capacity for the ArrowResponse stream |
reorg_safe_distance | u64 | 0 | Number of blocks behind the head to stay, to avoid reorged data |
Rust API Reference
See the ClientConfig rustdoc for all fields and methods.
RPC Client Querying
The Query type defines what data to fetch from the RPC endpoint.
Query Structure
Rust
#![allow(unused)]
fn main() {
use tiders_rpc_client::{Query, LogRequest, TransactionRequest, TraceRequest};
use tiders_rpc_client::{Fields, BlockFields, TransactionFields, LogFields, TraceFields};
let query = Query {
from_block: 18_000_000,
to_block: Some(18_001_000),
include_all_blocks: false,
logs: vec![LogRequest { .. }],
transactions: vec![TransactionRequest { .. }],
traces: vec![TraceRequest { .. }],
fields: Fields {
block: BlockFields { number: true, timestamp: true, ..Default::default() },
transaction: TransactionFields { hash: true, ..Default::default() },
log: LogFields { address: true, data: true, ..Default::default() },
trace: TraceFields::default(),
},
};
}Python
from tiders_core import ingest
query = ingest.Query(
kind=ingest.QueryKind.EVM,
params=ingest.evm.Query(
from_block=18_000_000,
to_block=18_001_000,
include_all_blocks=False,
logs=[ingest.evm.LogRequest(...)],
transactions=[ingest.evm.TransactionRequest(...)],
traces=[ingest.evm.TraceRequest(...)],
fields=ingest.evm.Fields(
block=ingest.evm.BlockFields(number=True, timestamp=True),
transaction=ingest.evm.TransactionFields(hash=True),
log=ingest.evm.LogFields(address=True, data=True),
trace=ingest.evm.TraceFields(),
),
),
)
| Option | Type | Default | Description |
|---|---|---|---|
from_block | u64 / int | 0 | First block to fetch (inclusive) |
to_block | Option<u64> / Optional[int] | None | Last block to fetch (inclusive). None means stream up to the current head |
include_all_blocks | bool | false | Fetch block headers even if no log/transaction/trace request is present |
logs | Vec<LogRequest> / list[LogRequest] | [] | Log filter requests |
transactions | Vec<TransactionRequest> / list[TransactionRequest] | [] | Transaction requests |
traces | Vec<TraceRequest> / list[TraceRequest] | [] | Trace requests |
fields | Fields | all false | Controls which columns appear in the output Arrow batches |
Log Requests
Filter logs by address and/or topics. Multiple addresses and topics are OR’d together by the provider.
Rust
#![allow(unused)]
fn main() {
LogRequest {
address: vec![Address::from_str("0xdAC17F958D2ee523a2206206994597C13D831ec7")?],
topic0: vec![topic0_hash],
include_blocks: true,
..Default::default()
}
}Python
ingest.evm.LogRequest(
address=["0xdAC17F958D2ee523a2206206994597C13D831ec7"],
topic0=[topic0_hash],
include_blocks=True,
)
| Option | Type | Default | Description |
|---|---|---|---|
address | Vec<Address> / list[str] | [] | Contract addresses to filter |
topic0 | Vec<Topic> / list[str] | [] | Event signature hashes |
topic1 | Vec<Topic> / list[str] | [] | First indexed parameter |
topic2 | Vec<Topic> / list[str] | [] | Second indexed parameter |
topic3 | Vec<Topic> / list[str] | [] | Third indexed parameter |
include_transactions | bool | false | Also fetch transactions for the same block range |
include_transaction_traces | bool | false | Also fetch traces for the same block range |
include_blocks | bool | false | Also fetch block headers for the same block range |
Log filters (addresses and topics) cannot be combined with include_* flags on the same LogRequest. When include_* flags activate additional pipelines, those pipelines return unfiltered data for the full block range. To use multi-pipeline coordination remove the log filters and filter post-indexing.
Transaction Requests
Activates the block pipeline to fetch blocks and transactions via eth_getBlockByNumber.
Rust
#![allow(unused)]
fn main() {
TransactionRequest {
include_logs: true,
include_blocks: true,
..Default::default()
}
}Python
ingest.evm.TransactionRequest(
include_logs=True,
include_blocks=True,
)
| Option | Type | Default | Description |
|---|---|---|---|
include_logs | bool | false | Also fetch logs for the same block range |
include_traces | bool | false | Also fetch traces for the same block range |
include_blocks | bool | false | Also fetch block headers (always fetched by this pipeline, included for API compatibility) |
TransactionRequest also exposes filter fields (from_, to, sighash, status, type_, contract_deployment_address, hash), but these are not supported by the RPC client. eth_getBlockByNumber returns all transactions in a block with no server-side filtering. Setting any of these fields will produce an error. This functionality is only supported on other tiders clients (SQD, HyperSync). Ingest all transactions and filter post-indexing in your tiders (Python) pipeline or database instead.
Trace Requests
Activates the trace pipeline to fetch internal call traces.
Rust
#![allow(unused)]
fn main() {
use tiders_rpc_client::TraceMethod;
TraceRequest {
trace_method: TraceMethod::TraceBlock, // or DebugTraceBlockByNumber
include_blocks: true,
..Default::default()
}
}Python
ingest.evm.TraceRequest(
include_blocks=True,
)
| Option | Type | Default | Description |
|---|---|---|---|
trace_method | TraceMethod | TraceBlock | TraceBlock (Parity-style) or DebugTraceBlockByNumber (Geth-style) |
include_transactions | bool | false | Also fetch transactions for the same block range |
include_transaction_logs | bool | false | Also fetch logs for the same block range |
include_blocks | bool | false | Also fetch block headers for the same block range |
TraceRequest also exposes filter fields (from_, to, address, call_type, reward_type, type_, sighash, author), but these are not supported by the RPC client. trace_block and debug_traceBlockByNumber return all traces in a block with no server-side filtering. Setting any of these fields will produce an error. This functionality is only supported on other tiders clients (SQD, HyperSync). Ingest all traces and filter post-indexing in your tiders (Python) pipeline or database instead.
Field Selection
Select only the fields you need to minimize data transfer. When all flags are false (the default), the full schema is returned.
Rust
#![allow(unused)]
fn main() {
Fields {
block: BlockFields { number: true, hash: true, timestamp: true, ..Default::default() },
transaction: TransactionFields { hash: true, from: true, to: true, value: true, ..Default::default() },
log: LogFields { address: true, data: true, topic0: true, ..Default::default() },
trace: TraceFields::default(),
}
}Python
ingest.evm.Fields(
block=ingest.evm.BlockFields(number=True, hash=True, timestamp=True),
transaction=ingest.evm.TransactionFields(hash=True, from_=True, to=True, value=True),
log=ingest.evm.LogFields(address=True, data=True, topic0=True),
trace=ingest.evm.TraceFields(),
)
Block Fields
| Field | Description |
|---|---|
number | Block number |
hash | Block hash |
parent_hash | Parent block hash |
nonce | Block nonce |
sha3_uncles | SHA3 of uncle blocks |
logs_bloom | Bloom filter for logs |
transactions_root | Merkle root of transactions |
state_root | Merkle root of state |
receipts_root | Merkle root of receipts |
miner | Block miner address |
difficulty | Block difficulty |
total_difficulty | Total chain difficulty |
extra_data | Extra data field |
size | Block size in bytes |
gas_limit | Block gas limit |
gas_used | Total gas used in block |
timestamp | Block timestamp |
uncles | Uncle block hashes |
base_fee_per_gas | EIP-1559 base fee |
blob_gas_used | EIP-4844 blob gas used |
excess_blob_gas | EIP-4844 excess blob gas |
parent_beacon_block_root | Parent beacon block root |
withdrawals_root | Merkle root of withdrawals |
withdrawals | Validator withdrawals |
l1_block_number | L1 block number (L2 chains) |
send_count | Send count (Arbitrum) |
send_root | Send root (Arbitrum) |
mix_hash | Mix hash |
Transaction Fields
| Field | Description |
|---|---|
block_hash | Block hash |
block_number | Block number |
from / from_ | Sender address |
gas | Gas provided |
gas_price | Gas price |
hash | Transaction hash |
input | Input data (calldata) |
nonce | Sender nonce |
to | Recipient address |
transaction_index | Index in block |
value | Value transferred (wei) |
v | Signature v |
r | Signature r |
s | Signature s |
max_priority_fee_per_gas | EIP-1559 max priority fee |
max_fee_per_gas | EIP-1559 max fee |
chain_id | Chain ID |
cumulative_gas_used | Cumulative gas used (receipt) |
effective_gas_price | Effective gas price (receipt) |
gas_used | Gas used by transaction (receipt) |
contract_address | Created contract address (receipt) |
logs_bloom | Bloom filter for logs (receipt) |
type_ | Transaction type |
root | State root (pre-Byzantium receipt) |
status | Success/failure (receipt) |
sighash | Function selector (first 4 bytes of input) |
y_parity | EIP-2930 y parity |
access_list | EIP-2930 access list |
l1_fee | L1 fee (Optimism) |
l1_gas_price | L1 gas price (Optimism) |
l1_fee_scalar | L1 fee scalar (Optimism) |
gas_used_for_l1 | Gas used for L1 (Arbitrum) |
max_fee_per_blob_gas | EIP-4844 max blob fee |
blob_versioned_hashes | EIP-4844 blob hashes |
deposit_nonce | Deposit nonce (Optimism) |
blob_gas_price | EIP-4844 blob gas price |
deposit_receipt_version | Deposit receipt version (Optimism) |
blob_gas_used | EIP-4844 blob gas used |
l1_base_fee_scalar | L1 base fee scalar (Optimism Ecotone) |
l1_blob_base_fee | L1 blob base fee (Optimism Ecotone) |
l1_blob_base_fee_scalar | L1 blob base fee scalar (Optimism Ecotone) |
l1_block_number | L1 block number (Optimism) |
mint | Minted value (Optimism) |
source_hash | Source hash (Optimism) |
Fields marked with (receipt) require eth_getBlockReceipts — the block pipeline fetches receipts automatically when any of these fields are selected.
Log Fields
| Field | Description |
|---|---|
removed | Whether log was removed due to reorg |
log_index | Log index in block |
transaction_index | Transaction index in block |
transaction_hash | Transaction hash |
block_hash | Block hash |
block_number | Block number |
address | Contract address that emitted the event |
data | Non-indexed event data |
topic0 | Event signature hash |
topic1 | First indexed parameter |
topic2 | Second indexed parameter |
topic3 | Third indexed parameter |
Trace Fields
| Field | Description |
|---|---|
from / from_ | Sender address |
to | Recipient address |
call_type | Call type (call, delegatecall, staticcall) |
gas | Gas provided |
input | Input data |
init | Contract creation code |
value | Value transferred |
author | Block reward recipient |
reward_type | Reward type (block, uncle) |
block_hash | Block hash |
block_number | Block number |
address | Created contract address |
code | Created contract code |
gas_used | Gas used |
output | Output data |
subtraces | Number of subtraces |
trace_address | Trace position in call tree |
transaction_hash | Transaction hash |
transaction_position | Transaction index in block |
type_ | Trace type (call, create, suicide, reward) |
error | Error message if reverted |
sighash | Function selector |
action_address | Self-destruct address |
balance | Self-destruct balance |
refund_address | Self-destruct refund address |
Response Format
The stream yields ArrowResponse items containing Arrow RecordBatches:
Rust
#![allow(unused)]
fn main() {
let mut stream = client.stream(query);
while let Some(response) = stream.next().await {
let response = response?;
// response.blocks — Arrow RecordBatch
// response.transactions — Arrow RecordBatch
// response.logs — Arrow RecordBatch
// response.traces — Arrow RecordBatch
}
}Rust API Reference
See the Query rustdoc for all fields.
Adaptive Concurrency
The RPC client automatically adjusts its parallelism and request pacing based on provider responses, maximizing throughput without overwhelming the provider or hitting rate limits.
There are three independent adaptive concurrency controllers, one for each type of RPC call pattern. Each controller’s value determines how many parallel tasks run concurrently for that pipeline.
| Controller | Used by | Initial | Min | Max |
|---|---|---|---|---|
| Block | Block pipeline (eth_getBlockByNumber batches) | 10 | 2 | 200 |
| Log | Log pipeline (eth_getLogs batches) | 10 | 2 | 200 |
| Single-block | Traces (trace_block, debug_traceBlockByNumber) and tx receipts (eth_getBlockReceipts) | 100 | 10 | 2000 |
The single-block controller is shared between traces and transaction receipts requests. It starts more aggressively because per-block calls are smaller and faster than batch calls.
How It Works
All controllers use the same adaptive algorithm, implemented lock-free with atomics.
Scaling Up
On each successful RPC call:
- Backoff delay is reduced by 25%
- A consecutive success counter increments
- After reaching the scale-up threshold, concurrency increases:
- Block and log controllers: +20% after 10 consecutive successes
- Single-block controller: +33% after 50 consecutive successes
The single-block controller requires more consecutive successes before scaling up because it runs many more concurrent calls.
Scaling Down on Rate Limits
When a rate-limit error is detected (HTTP 429 or provider rate-limit message):
- Consecutive success counter resets to 0
- Backoff delay doubles (starting from 500 ms, capped at 30 s)
- Concurrency is halved (down to the minimum)
Scaling Down on General Errors
When a non-rate-limit error occurs:
- Consecutive success counter resets to 0
- Concurrency is reduced by 10% (gentler than rate limits)
Chunk Size Adaptation
The block and log controllers also adapt the chunk size — the number of blocks per RPC call.
| Controller | Default chunk size |
|---|---|
| Block | 200 blocks |
| Log | 1000 blocks |
| Single-block | 200 blocks (batch grouping only, each block is a separate call) |
The initial chunk size can be set by the batch_size configuration option.
Block Range Fallback
When a provider rejects a request because the block range is too large, the log controller tries to parse the error to extract a suggested range. It understands error formats from many providers:
- Alchemy —
"this block range should work: [0x..., 0x...]" - Infura / Thirdweb / zkSync / Tenderly —
"try with this block range [0x..., 0x...]" - Ankr —
"block range is too wide" - QuickNode / 1RPC / zkEVM / Blast / BlockPI —
"limited to a 10,000" - Base —
"block range too large"
When no provider hint is available, the pipeline falls through a tiered fallback: 5000 → 500 → 75 → 50 → 45 → 40 → 35 → 30 → 25 → 20 → 15 → 10 → 5 → 1 blocks.
The block controller uses a simpler strategy: on block-range errors it halves the range.
Chunk Size Recovery
After chunk size has been reduced due to errors, the block and log controllers periodically attempt to reset it to the original value. On each successful call, there is a 10% probability of resetting the chunk size back to the configured (or default) value. This allows the system to recover from temporary provider issues without permanently degrading throughput.
Backoff
Each controller maintains a backoff delay that is applied before every RPC call:
- Starts at 0 ms (no delay)
- On rate limit: doubles, starting from 500 ms, capped at 30 s
- On success: reduced by 25% per call
- Backoff applies to all concurrent calls sharing the same controller
Rust API Reference
The Rust API documentation is auto-generated from source code using rustdoc. It provides detailed documentation for every public type, function, and module.
Browse the API
- tiders-core — re-exports all core crates
- tiders-ingest — data ingestion and streaming
- tiders-evm-decode — EVM ABI decoding
- tiders-svm-decode — Solana instruction decoding
- tiders-cast — type casting
- tiders-evm-schema — EVM Arrow schemas
- tiders-svm-schema — SVM Arrow schemas
- tiders-query — query execution
- tiders-rpc-client — EVM RPC data fetcher
Building the API Docs Locally
To generate the rustdoc output locally:
# tiders-core (all crates)
cd tiders-core
cargo doc --no-deps --workspace
# tiders-rpc-client
cd tiders-rpc-client/rust
cargo doc --no-deps
# Open in browser
open target/doc/tiders_core/index.html
Architeture
This section walks you through how is tiders architecture.
Dependency Graph
tiders-evm-schema (no deps)
tiders-svm-schema (no deps)
tiders-cast (no deps)
tiders-query (no deps)
tiders-evm-decode (no deps)
tiders-svm-decode (no deps)
│
├──► tiders-rpc-client
│ └── tiders-evm-schema
│
├──► tiders-ingest
│ ├── tiders-evm-schema
│ ├── tiders-svm-schema
│ ├── tiders-cast
│ ├── tiders-query
│ └── tiders-rpc-client
│
├──► tiders-core
│ ├── tiders-evm-schema
│ ├── tiders-svm-schema
│ ├── tiders-cast
│ ├── tiders-query
│ ├── tiders-evm-decode
│ ├── tiders-svm-decode
│ └── tiders-ingest
│
└──► tiders-core-python
└── tiders-core (aliased as "baselib")